
So, you've decided to build a data lake – great news! Data lakes can be incredibly useful. However, as I explained in my earlier post, it can be challenging to move past over-hyped promises and unrealistic expectations to capture the real value of data lakes.
I’m sure you’re eager to get started. But before you jump straight to implementation, keep in mind that it takes a lot of planning and thought to build a data lake that’s more than just a mono-tasking problem solver.
The power and flexibility data lakes offer come at a cost – complexity. Not only do you have to pick the right combination of technologies, you must ensure that they will all work together now and in the future. Then there are the not-so-minor details of data lake governance and security. Unsecured data lakes are a nightmare for everyone.
Here are a few other things to consider:
- At some point, you're going to want to add more data sources to support exciting new applications. Machine learning, anyone?
- Eventually you're going to want to give more control to the end users. “Can we have an analytics sandbox, please?”
- You might even want to integrate data from your enterprise data warehouse. (Cue spooky music…)
With these tough decisions ahead of you, it's safe to say you need a plan. Let's start by looking at three common pitfalls people face when implementing data lakes – and what you can do to avoid them.
Tip #1: Create a data and analytics strategy – and make sure you understand the big picture
Get out your comprehensive, 500-page data and analytics strategy document that maps out your organization's principles, goals, integration approaches, technology road map and implementation strategies.
You don't have one of those? Well, that might be a problem. You need to decide where you're going before you can figure out how to get there. Hopefully it won’t take 500 pages.
So, what exactly IS a “data and analytics strategy?”
First, we're talking about building a data lake and not a data puddle. Sound silly? Maybe so – but it’s a serious point. A data lake is only one part of an entire ecosystem of source systems, ingest pipelines, integration and data processing technologies, databases, metadata, analytics engines and data access layers. Your data and analytics strategy should be able to answer questions about each of these components, in as much detail as necessary.
Sounds good, but where to begin? One approach is to start with a capability model. Think of it as a diagram showing the parts that make up a complex system, how they fit together and what each of the parts do to make the whole system work.
Following is a capability model of a modern data and analytics ecosystem.
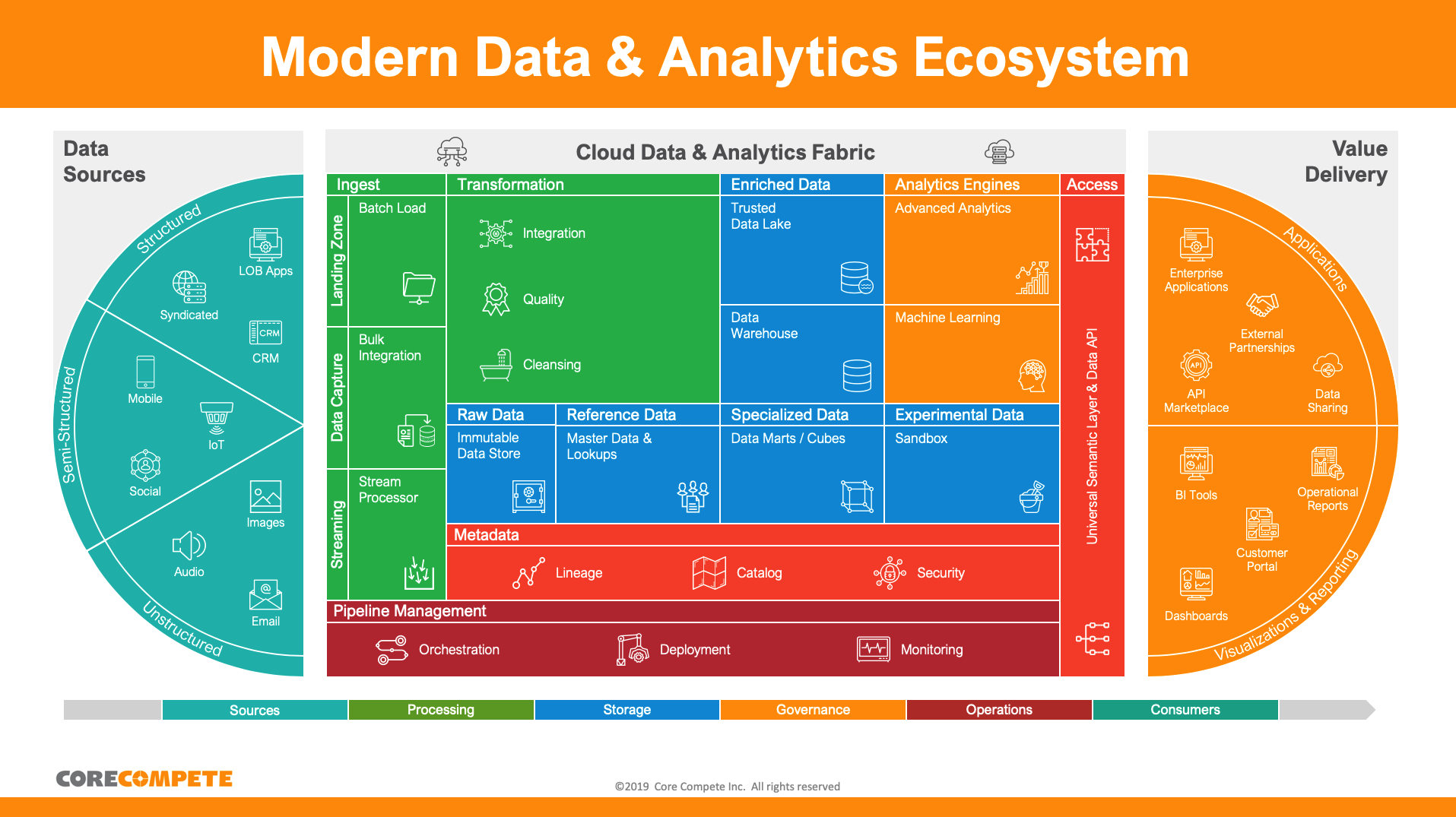
Once you've got a good capability model, make it your own. You should start by deciding which parts are relevant. Perhaps you don't need real-time ingestion or image data. No problem. Get rid of those pieces. Maybe machine learning is something you're keen to play with, but you're not quite ready for it. Keep it – but label it for future exploration.
The point of a capability model is to start conversations on what the system needs to do (now, and in the future), what services are required to accomplish these goals, and how all the parts fit together.
Once you’ve got your data and analytics strategy sorted, you’re on the road to success.
Tip #2: Pick the right technologies for your business needs – and remember that lack of experience and expertise can lead to mistakes, false starts and risk
So, what technologies should you use to build your data lake?
I suggest you go back to the capability model. Once you've figured out what parts are in your data ecosystem, you can research best-of-breed technologies, plug it all in and everything will work together. Right? Well…you might get lucky – but not all technologies play nicely together. You might not even need the power of top-of-the-line tools. Cost could be a factor too, unless your CFO told you: "Budget is no concern - spare no expense." (Ever had a CFO say this to you?)
In any case, you should be prepared to answer a few questions about each of your technology choices:
- Will the technology meet my needs today and in the future?
- Will the technologies work with each other?
- Will they work with my existing IT systems?
- Who will build the data lake and integrate it with the larger data ecosystem?
The last point is especially important. If your IT group has people with the right skills, experience and bandwidth, you should absolutely ask them for help. If not, you probably need to look for outside assistance. If you’ve chosen an end-to-end solution, you can always go to the vendor's partner program. If you've decided to blend together your own solution from a mix of open source and commercial products, it might be a bit harder. Look for advisers who have expertise with a wide array of technologies and integrations. Certifications are good, too.
Whether you choose to hire help or go it alone, technology selection is a super important part of planning your data lake. Once the tech stack is nailed down and you’ve finalized the architecture, you're ready to start development.
But not too fast. You're not quite done with the planning part.
Tip #3: Create an ongoing support plan – don’t assume your commitment will end when the project is finished
When putting together a plan for building a data lake, don't forget maintenance and management. Who is going to keep the lights on? Who will make sure that the pipelines feeding your data lake don't get gunked up with corrupted or malformed source data? How are you going to handle important governance issues like security, access control and operations?
Sure, cloud-native data and analytics platforms are built from the ground up for redundancy and reliability. Some can even virtually eliminate downtime. A data lake built on these technologies should provide trouble-free operations for all your application needs. Except when it doesn’t.
The thing to remember about any data ecosystem is that it is made up of a lot of moving parts – pipelines, storage, data engine and access layer components. Someone is going to have to monitor, tune and troubleshoot these parts as well as all the custom application code you've built to use that data. (You did remember to include monitoring in your system, right?)
Make sure you've got your support needs covered.
“By failing to prepare, you are preparing to fail.”
Benjamin Franklin may or may not have said this – and if he did, I’m pretty sure he wasn’t talking about data lakes. But the message still applies. Without a comprehensive, forward-thinking plan, your shiny new data lake could end up difficult to navigate, slow, expensive and – perhaps worst of all – not terribly useful.
If that happens, you'll be the proud new owner of a data swamp instead of a data lake. And nobody wants a data swamp.
Learn more about it in this article: "What is a data lake and why does it matter?"





3 Comments
Great article. Simple and straight forward to the point
Great piece Khari, I think it is extremely important to use a tool that will continue to provide many benefits in the future.
Great article for me and my team Synodus