As machine learning takes its place in numerous advances within the marketing ecosystem, the interpretability of these modernized algorithmic approaches grows in importance. According to my SAS peer Ilknur Kaynar Kabul:
We are surrounded with applications powered by machine learning, and we’re personally affected by the decisions made by machines more and more every day.
Her writing has inspired me to consider how machine learning is used for customer analytics and personalized marketing. Emerging machine learning applications for business-to-consumer (B2C) use cases range from:
- Customer journey optimization.
- Acquisition marketing (or lead scoring).
- Upsell and cross-sell propensity models.
- Pricing optimization.
- Traffic and demand forecasting.
- Retention (or decreasing churn).
- Ad targeting.
These uses should sound familiar to any data-driven marketer. However, machine learning grabs the baton from classical statistical analysis by increasing accuracy, context and precision. A wide variety of business problems can incrementally benefit from algorithms like forests, gradient boosting or support vector machines that most users know very little about. When it comes to influencing stakeholders, marketing analysts often put emphasis on the prediction accuracy of their models – not on understanding how those predictions are actually made.
For example, do you really care why individuals click on a display media ad? As long as you get more clicks, some might be satisfied because key performance indicators are trending positively. Give me the algorithm that maximizes media performance and spare me the details. Black box, white box, it doesn’t matter. I got things to do.
However, others genuinely care about both analytical precision and explanatory insights that reveal why some tactics work better than others. If you have a conversion goal on your website, then identifying individuals who have higher propensities to meet that objective is part of the recipe, but understanding the drivers of that behavior could inform:
- Look-a-like segmentation to acquire higher quality leads.
- A/B, MAB, and MVT testing strategies like call-to-action tactical optimization.
- Channel and journey attribution measurement for conversion goal insights.
Are complex models impossible to understand?
Interpretability of machine learning models is a multifaceted and evolving topic. Some applications are easy to understand, commonly referred to as white box (transparent) models. They provide us the opportunity to explain a model’s mechanisms and predictions in understandable terms. In other words, we are removing the unanswerable question of “why this” or “why that” from the conversation.
Imagine a scenario where analysts can tell a data story about how changing the strategic levers (inputs) will affect the predicted outcome, as well as provide the justifications. It’s a beautiful outcome when technical and non-technical audiences can walk away with a clear understanding of a refinement in marketing strategy at the end of a meeting.
However, with the recent advances in machine learning and artificial intelligence, models have become very complex, including deep neural networks or ensembles of different models. We refer to these specific examples as black box models.
Unfortunately, the complexity that gives extraordinary predictive abilities also makes black box models challenging to understand and trust. They generally don’t provide a clear explanation of why they made a certain prediction. They give us a probability that is actionable, yet hard to determine how we arrived at that score. Here are a few examples:
- Digital data such as website clickstream and offsite ad-serving are some of the original inspirations for the heavily-used term: “big data”. There can be thousands (even millions) of features in machine learning models for marketing use cases.
- There’s no one-to-one relationship between input features and estimated parameters.
- Often, the combinations of multiple models affect the prediction.
- Machine learning algorithms are data-hungry. Some need enormous amounts to achieve high accuracy.
Brands experimenting with machine learning are questioning whether they can trust the models, and if fair decisions can be made using them.
If an analyst cannot figure out what they learned from those data sets, and which of those data points have more influence on the outcome than the others, how can they tell a practical story to the broader business, and recommend taking action? I don’t know the sort of presentations you give, but if I’m encouraging a senior leader to alter their direction, I want them to be able to explain why specific outcomes end positively or negatively to their leadership team. Shrugging one’s shoulder and saying “I don’t know why we made or lost an additional $5 million dollars” just feels dangerous.

What happens if the algorithm learns the wrong thing? What happens if they are not ready for deployment within your channel touchpoint technology? There is a risk of misrepresentation, oversimplification or overfitting. That’s why you need to be careful when using them, or the promise of consumer hyper-personalization may never be fulfilled.
Isn’t being accurate good enough?
In machine learning, accuracy is measured by comparing predictions to the known actual values from the input data set. The higher the accuracy, the better, right? Not exactly. In marketing, classification models are very popular. Who is likely to convert, and who isn’t? This question begs more questions:
- Does leadership want to be as accurate as possible in predicting both conversion and non-conversion behavior?
- Do they care more about precision and maximizing conversion behavior only on their targeting efforts, while accepting more errors on non-conversion predictability?
Based on your brand’s business drivers, these can suddenly become tricky questions to answer. The choice made will impact the financial profitability (or loss) based on the approach chosen.
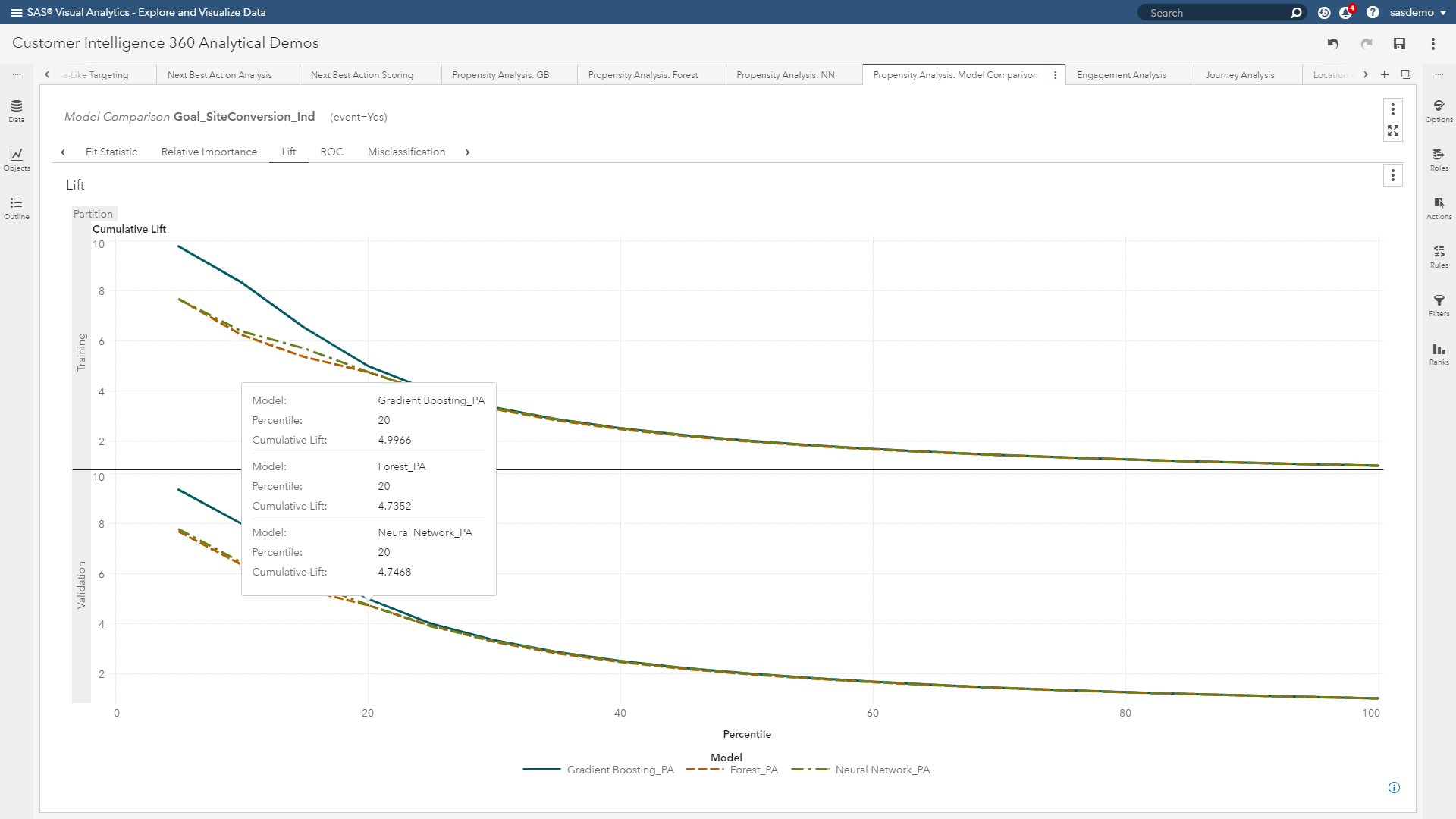
Those of you reading this who have built models before will quickly recognize that I am referring to model assessment through diagnostics such as lift curves, ROC plots, misclassification charts and confusion matrices.
In the world of machine learning, it isn’t enough.
A machine learning model can achieve high accuracy by memorizing the seemingly unimportant features or patterns in your data. If there is a bias in your input data, this can lead to a poor representation of the predictions in a production environment in which the insights are deployed. How many of you want to target incorrect segments, provide irrelevant offers, or misrepresent your brand at customer touchpoints? Not me.
You cannot rely only on prediction accuracy. You need to know more. You need to demystify the black box and improve transparency to make machine learning models trustworthy and reliable.
Takeaways
SAS’s vision is to help digital marketers be effective through analytic techniques. Consumer preferences are hard to predict. By using SAS’s deep library of algorithms within SAS Customer Intelligence 360, machine learning can be embraced, rather than resisted, to create relevancy through data-driven personalization.
This article summarized some of the present-day challenges in the adoption of machine learning. Now we need further details on questions like:
- Do marketers and consumers really need interpretability from machine learning?
- When is interpretability needed within a brand’s adoption curve of analytics?
In part two of this blog posting series, we will dive into these topics.

1 Comment
Pingback: SAS Customer Intelligence 360: Hybrid marketing and analytic's last mile [Part 1] - Customer Intelligence Blog