In my previous post I wrote about the Atari video game, Breakout, and how an AI technique (reinforcement learning, or RL) outperformed a human player. I also drew an analogy between Breakout and customer journey optimization. In Breakout, the environment is what you see on the screen – the blocks, bat and ball. The  computer learns the best actions to take (bat movements) in response to the current and previous states of the game (position and track of ball and remaining blocks). The aim is to maximize the score by hitting the ball with the bat to break all the blocks. The game proceeds through a series of increasingly difficult levels.
computer learns the best actions to take (bat movements) in response to the current and previous states of the game (position and track of ball and remaining blocks). The aim is to maximize the score by hitting the ball with the bat to break all the blocks. The game proceeds through a series of increasingly difficult levels.
For customer journeys, the environment consists of a set of customers and potential marketing messages (actions). The marketer wins the game by finding actions to take on customers that lead to the highest score. The score can be measured in terms of total number of conversions, or via a value metric. The customer states are described using any customer attribute that may affect the way they respond to a creative, such as:
- Demographic information (gender, income, age, location, etc.).
- Visitor behavior (the touch point they are currently interacting through, current session information such as page visited, time since last visit, etc.).
- History (creatives, messages or promotions have been provided in the past and the response).
The actions become the various marketing messages that can be promoted at the current interaction point. State transitions represent the steps in the customer journey and the state action value is the incremental value expected when taking a specific action on a customer.
The decision-making process is simple once these values have been calculated. Just take the action with the greatest expected value. This is a familiar concept to marketers who are used to conventional next-best-offer systems. The revolutionary difference offered by RL is in the holistic way that the system learns the values.
In a classic next-best-action approach, you build one predictive model for each offer, and these models are independent of each other. It is difficult to add interaction effects, such as how do last week’s 10 percent offer and yesterday’s additions to their basket combine to affect the likelihood of conversion on the free shipping offer. It’s not impossible, you can build multiple models and create attributes to incorporate these interaction effects. But it rapidly becomes impractical as the number of combinations explode. And as the combinations explode, the data available to model each distinct case becomes very sparse, reducing the chances of finding a good model.
RL, by contrast, takes a holistic approach. The states themselves contain the interaction history automatically, so no need to create additional attributes. The biggest difference is the dynamic nature of the learning process. It quickly determines which states occur more frequently and focuses effort on these. This means that the data is not spread out over a large number of hypothetical possible combinations of actions and is used more efficiently. Some randomness is retained in the system so that it occasionally tries different combinations to prevent it becoming stale and self-fulfilling.
The objective that plays the role of score can be a measure of overall conversion or customer value or sales revenue. The aim of the game is to maximize this, either in the long term or short term.
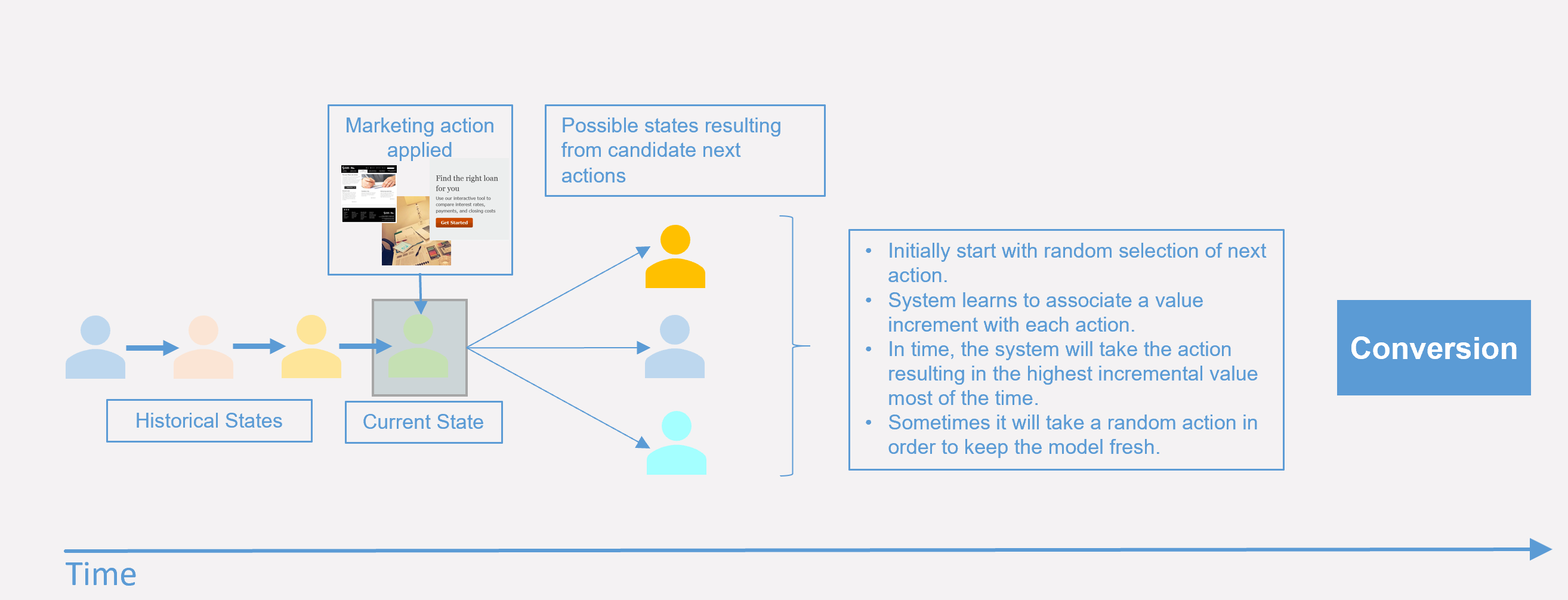
The diagram above shows a simplified customer journey. Each colored rectangle represents a different state for the customer. This state is described by things we know about the customer. Some of these are things that rarely change (for example, demographics) and some change more frequently, such as measured behavior. At each state there are one or more candidate actions (i.e., activities the marketer can perform). Each of these marketing actions can lead to a new state, and there is a value associated with this transition (the so-called state-action value). If we know what this value is then we can be sure that we are making the best possible decisions.
Some of these state transitions are a result of marketing activities; others may be spontaneous or a result of external influences. Consider the highlighted state in our customer’s path. Our customer qualifies for three marketing activities and the question is which of these to promote. Initially, the system knows nothing about the value accruing from a given action.
Taking random actions (for example, delivering one out of a set of messages) is one approach to starting the learning process. If that action leads directly to a reward (e.g., a conversion) then calculating the state action value is easy if you are prepared to concentrate on short-term optimization and want to ignore previous steps in the journey. However, it is this longer-term effect and being able to take into account the sequence (or experience) that distinguishes our approach to journey optimization.
Hopefully you will find this analogy between using AI to win at video games and using AI to win at marketing meaningful for your marketing efforts. Part 3 (upcoming) of this series illustrates the inner workings of RL and its application to customer journey optimization.

4 Comments
Awesome posts of this series!!! Very useful.
Quick question, do you know or come across any of our customers, banking customer preferred if any, that the uplifted performance using RL compared with conventional individual predictive models for NBO use case - ie. increase in response in %, or increase sale amount%, or ROI; Also the time and effort significantly reduced in % if any. Thanks!
Hi Irene,
I'm not aware of any studies though it is very early days in the adoption of RL techniques.
THanks, Malcolm
Great insight Malcolm! Can you point me to an article which explaines RI in more depth (for high level presales people without a PhD ;).
Thanks,
Manuel
Hi Manuel,
Have a look at part three of the series where I tried to do exactly this. Let me know if this meets your needs and if not I can try again :) One of the reasons I wrote it was because existing on-line explanations seem to be either very simplistic or, as you say, PhD level maths.