Niemal każdego dnia słyszymy doniesienia o nowych osiągnięciach w dziedzinie sztucznej inteligencji i uczenia maszynowego. Co prawda, do stworzenia odpowiednika ludzkiej inteligencji w sensie szerokim i ogólnym trochę nam jeszcze brakuje, ale coraz częściej maszyny są w stanie rozwiązywać problemy, z którymi do niedawna jedynie człowiek mógł sobie poradzić. Przykładami takich problemów są rozpoznawanie obrazów, komunikowanie się za pomocą języka naturalnego czy tworzenie muzyki.
Skupmy się jednak na samym rozpoznawaniu obrazów – dziedzinie zwanej także widzeniem komputerowym (ang. computer vision). Polega ona na interpretacji tego, co widzimy na zdjęciu czy na obrazku. Rzecz wydaje się banalnie prosta nawet dla kilkuletniego dziecka. Zgodnie z popularną anegdotą, to samo pomyślał w 1966 roku Seymour Papert ze słynnego Massachusetts Institute of Technology: zaproponował on jako projekt na lato dla kilku studentów podłączenie kamery do komputera i stworzenie oprogramowania, które miało opisać „to, co widzi komputer”. Szybko okazało się, że problem jest „nieco” bardziej skomplikowany i w ten sposób powstała dziedzina rozpoznawania obrazów. Być może anegdota ta nieco ubarwia rzeczywistość, ale faktem jest, że problem rozpoznawania obiektów na zdjęciach został w sposób zadowalający rozwiązany dopiero po zastosowaniu głębokich sieci neuronowych w okolicach 2012 roku, a więc blisko 50 lat później. Od tego momentu to, co było wcześniej zbiorem zer i jedynek reprezentujących obraz, stało się dla maszyn możliwym do interpretacji obrazem zawierającym konkretne obiekty i pokazującym konkretne sceny (Rysunek 1.).
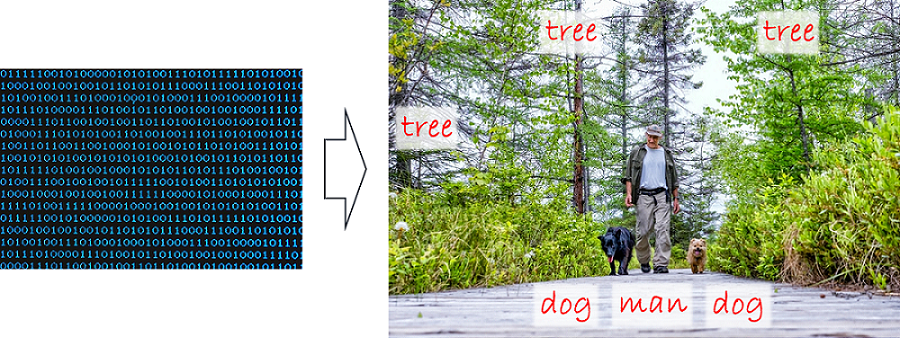 Rysunek 1. Surowe zdjęcie (reprezentacja cyfrowa obrazu) oraz interpretacja („mężczyzna z psami na spacerze w lesie")
Rysunek 1. Surowe zdjęcie (reprezentacja cyfrowa obrazu) oraz interpretacja („mężczyzna z psami na spacerze w lesie")
Jak to działa? Dla pełnego zrozumienia niezbędne jest poszerzenie wiedzy o podstawach działania sztucznych sieci neuronowych oraz o specjalizowanych sieciach do rozpoznawania obrazu – tzw. sieciach konwolucyjnych (ang. convolutional neural networks, CNN). W skrócie, sieci takie działają w sposób zbliżony do systemu wizyjnego w korze mózgowej człowieka. W mózgu człowieka konkretne neurony odpowiedzialne za analizę widzianego obrazu reagują jedynie na bodźce wzrokowe pojawiające się w konkretnej części pola widzenia, zwanej polem recepcyjnym (ignorując bodźce spoza pola recepcyjnego). Pola recepcyjne poszczególnych neuronów nakładają się na siebie, pokrywając całe pole widzenia. Neurony wizyjne przetwarzają wizualne bodźce wejściowe na sygnały przekazywane do kolejnych neuronów w mózgu, które kontynuują przetwarzanie. Podobnie działa sztuczna sieć neuronowa typu CNN, gdzie sztuczne neurony analizujące obraz podłączone są do fragmentów obrazu – a konkretnie do wejść sieci odpowiadających wartościom liczbowym pikseli z danego fragmentu obrazu (Rysunek 2.).
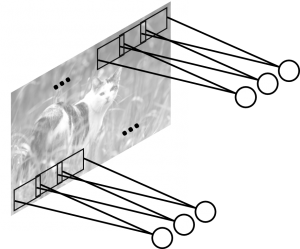 Rysunek 2. Neurony w sieci CNN podłączone do fragmentów obrazu wejściowego
Rysunek 2. Neurony w sieci CNN podłączone do fragmentów obrazu wejściowego
Pojedynczy neuron odpowiedzialny jest za „wykrywanie” konkretnych kształtów pojawiających się w jego polu recepcyjnym. To, jaki kształt jest wykrywany przez dany neuron, zależy od wartości tzw. wag przypisanych każdemu połączeniu tego neuronu z wejściowym pikselem obrazu. Co ciekawe, wagi te ustalają się same podczas procesu uczenia sztucznej sieci neuronowej. Innymi słowy, na podstawie celu (np. rozpoznawanie gatunków zwierząt na zdjęciach) oraz danych trenujących (zdjęcia zwierząt z przypisaną informacją o gatunku), sieć neuronowa sama „decyduje”, jakie kształty muszą być wykrywane w obrazie, aby zrealizować cel (rozróżniać gatunki zwierząt). Podobnie jak w mózgu człowieka, opisywane do tej pory neurony z pierwszej warstwy sztucznej sieci neuronowej przekazują sygnały do kolejnych warstw sieci, które kontynuują przetwarzanie – np. wykrywając coraz bardziej złożone kształty.
Sieci neuronowe trenowane na dużych zbiorach zdjęć osiągają imponujące rezultaty – w 2015 roku po raz pierwszy błąd w rozpoznawaniu obiektów na bazie testowej ImageNet (1000 kategorii obiektów) spadł poniżej błędu „ludzkiego”, czyli około 5,1%. Warto dodać, że tuż przed erą głębokich sieci neuronowych, najlepsze algorytmy rozpoznające obiekty osiągały błąd rzędu 25-30% (2012 rok). Ponadto, można powiedzieć, że błędy popełniane przez algorytmy AI mają często „ludzki” charakter, tzn. na pierwszy rzut oka można wytłumaczyć, dlaczego system się pomylił (przykład – Rysunek 3.). Jest to jeden z pierwszych przykładów pokazujących, że sztuczna inteligencja małymi krokami upodabnia się do sposobu postrzegania rzeczywistości przez człowieka.
 Rysunek 3. „Ludzka” pomyłka – wg. AI to bajgiel lub kot burmański
Rysunek 3. „Ludzka” pomyłka – wg. AI to bajgiel lub kot burmański
No dobrze, powiedzmy, że sztuczna inteligencja nauczyła się „rozumieć” obrazy, ale jakie możliwości to przed nami otwiera? Czy jest to tylko ciekawostka, czy rzeczywiście można taką funkcjonalność maszyn wykorzystać np. w biznesie? Przykłady takich firm jak Google czy Facebook pokazują, że technologia ta już znajduje liczne zastosowania. Analiza zdjęć użytkowników, automatyczne ich grupowanie, odczytywanie z nich informacji o zainteresowaniach, rozpoznawanie twarzy znajomych – to jedne z pierwszych zastosowań. Ale nie tylko internetowi giganci korzystają z automatycznego rozpoznawania obrazów. Firmy z branży reklamowej i sami producenci są zainteresowani wykrywaniem i rozpoznawaniem logotypów (i produktów) w treściach foto/wideo. W Australii latające drony będą wkrótce ostrzegały przed rekinami zbliżającymi się do plaży. Również autonomiczne samochody bazują w coraz większym stopniu na analizie obrazu z kamer, które stają się głównym czujnikiem wykorzystywanym do zrozumienia sytuacji na drodze. Te i inne przykłady dowodzą, że zdolność maszyn do interpretacji obrazu ma bardzo szerokie zastosowanie praktyczne.
Potencjał widzenia komputerowego dostrzega także SAS. Narzędzia SAS wykorzystywane były w takich projektach jak analiza zdjęć samochodów po wypadkach dla branży ubezpieczeniowej czy wykrywanie nieprawidłowości w procesie produkcji półprzewodników na podstawie zdjęć wafli krzemowych. W kolejnej odsłonie nowoczesnej platformy SAS Viya, zapowiadanej na jesień 2017, możemy spodziewać się nowego modułu wspierającego tzw. uczenie głębokie (ang. deep learning). Moduł umożliwi między innymi trenowanie i wdrażanie głębokich sieci neuronowych, takich jak właśnie sieci konwolucyjne czy wykorzystywane w przetwarzaniu języka naturalnego sieci rekurencyjne. SAS Viya posiada także zbiór funkcji dedykowanych do przetwarzania obrazów, oraz umożliwia łatwą integrację z istniejącymi platformami open-source (w tym wkrótce również możliwość importu i eksportu gotowych modeli głębokich).

1 Comment
Świetny artykuł ! Ale ... Zgodzi się Pan, że pewnych sformułowań używa Pan (zresztą jak większość w tej dziedzinie) marketingowo. Po pierwsze sztuczna inteligencja dalej jest sztuczna tzn ma za zadanie rozwiązać problem zakwalifikowania elementów obrazu do wcześniej określonych wzorców. Określone wzorce to druga rzecz o której się tu nie wspomina bo jeśli analiza przeprowadzana jest na podstawie powiedzmy 10000 zdjęć to raz, że ktoś do tych zdjęć musiał dodać info co na nich jest (maszyna ani algorytm tego nie zrobiły) czyli kombinacja pikseli w określonej przestrzeni zdjęcia to "coś" a inna to coś innego, a dwa jeśli te zdjęcia wybrałbym bardzo "monotematycznie" to błędy będą brać się z tego, że na 10001 zdjęciu umieszczę coś jeszcze czego np nie było w 10000 poprzednich. Używanie określeń o inteligencji (jak z teleportacją - staje się jasne jak doda się, że z kwantową) jest trochę dziwne bo tak naprawdę polepszamy algorytmy klasyfikujące i grupujące a istotnym rozwinięciem technologicznym jest to, że w krótkim czasie program może przeanalizować miliardy zer i jedynek i powybierać rozwiązania ze wszystkich możliwości (dlatego często przegrywamy w szachy z dobrymi programami - one nie wiedzą nawet, że wygrywają - przestają działać gdy kończy się gra 😉 ) . Pozdrawiam serdecznie i do zobaczenia w SAS .