Find out how analytics, from data mining to cognitive computing, is changing the way we do business
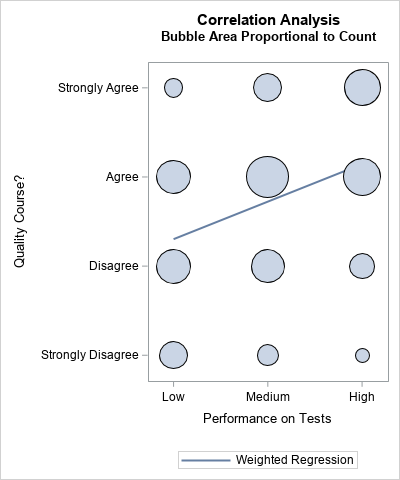
The difference between frequencies and weights in a correlation analysis

Statistical software often includes supports for a weight variable. Many SAS procedures make a distinction between integer frequencies and more general "importance weights." Frequencies are supported by using the FREQ statement in SAS procedures; general weights are supported by using the WEIGHT statement. An exception is PROC FREQ, which contains