IT organizations today are constantly challenged to do more with less. Reusing data processing jobs and employing best practices in monitoring the health of your data are proven ways to improve the productivity of data professionals. Dataflux Data Management Studio is a component of both the SAS Data Quality and the SAS Data Management offerings that allows you to create data processing jobs to integrate, cleanse and monitor your data.
You can write global functions for SAS Data Management jobs that can be reused in any expression in the system, in either data or process flow jobs. Global functions can be called from expression nodes, monitor rules, profile filters, surviving record indicators, process flow if-nodes and more.
Global functions are defined in a text file and saved in the Data Management installation directory under “etc/udf” in Data Management Studio or Data Management Server respectively.
Each global function has to have a unique name and is wrapped with a function / end function block code, can process any number of input parameters and returns a single value of either integer, real, date, string or boolean type.
Hello World
For a start, let’s create a “hello world” function.
- If it does not exist, create a folder in the installation directory under “etc/udf” (DM Studio and DM Server).
- In “etc/udf” create a file named hello_world.txt.
- In the hello_word file create the function as follows:
function hello_world return string return “hello world!” end function |
- Save the file and restart DM Studio, if necessary, in order to use hello_world().
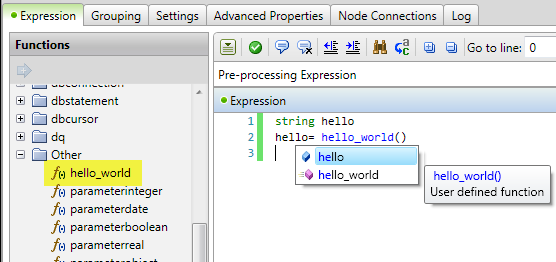
The new function is fully integrated in Data Management Studio. You can see the new function in an expression node under Function->Other or as expression language help in the expression node editor.
Handling Parameters
Global functions can handle any number of parameters. Parameter helper functions are available to access input parameters inside a function:
- paramatercount() returns the number parameters that have been passed into the function call. This is helpful if the incoming parameters are unknown.
integer i for i = 1 to parametercount() begin // process each parameter end |
- parametertype(integer) returns the type of the parameter for the given parameter position. The first parameter is 1. The return value will either be integer, real, date, string or Boolean.
- parameterstring(integer), parameterinteger(integer), parameterboolean(integer), parameterdate(integer), parameterreal(integer) these functions return the value of the parameter as specified by position, or null if the parameter doesn’t exist. You can use these functions if you know the incoming parameter type at a given position.
- parameter(integer) returns the value of the parameter as specified by position, or null if the parameter doesn’t exist. If you don’t know the incoming parameter type you can use this function. Note: Using the parameter() function may require additional overhead to coerce the values to the field type. Using the specific data type parameter functions above will eliminate the cost of coercion.
Global Function Example
This global function will check if password rules are followed.
////////////////////////////////////////////////////////////////////////// // Function: check_psw_rule // Inputs: string // Output: boolean -> true == passed check; false == failed check // Description: Check the rules for password. The rules are: // Need to be at least 8 characters long // Need to have at least one lower case character // Need to have at least one upper case character // Need to have at least one number ////////////////////////////////////////////////////////////////////////// function check_psw_rule return boolean string check_str boolean rc regex r check_str= parameterstring(1) //copy input parameter to variable rc= false //set default return value to failed (false) if(len(check_str) < 8) //check if at least 8 characters return rc r.compile("[a-z]") if (!r.findfirst(check_str)) //check if at least one lower case character return rc r.compile("[A-Z]") if (!r.findfirst(check_str)) //check if at least one upper case character return rc r.compile("[0-9]") if (!r.findfirst(check_str)) //check if at least one number return rc rc= true //return true if all checks passed return rc end function |
This function can be called from any expression in a Data Management job:
boolean check_result check_result= check_psw_rule(password) |
Global function can also call other global function
Just a few things to be aware of. There is a late binding process, which means if function B() wants to call function A(), then function A() needs to be loaded first. The files global functions are stored in are loaded alphabetically by file name. This means the file name containing function A() has to occurs alphabetically before file name containing function B().
Best Practices
Here are some best practice tips which will help you to be most successful writing global functions:
- Create one file per expression function.
This allows for global functions to easily be deployed and shared. - Use lots of comments.
Describe what the function’s purpose, expected parameters, and outputs and improve the readability and reusability of your code - Test the expressions in data jobs first.
Write a global function body as an expression first and test it via preview. This way it is easier to find typos, syntax errors and to ensure that the code is doing what you would like it to do. - Debugging - If the global function is not loading, check the platform_date.log. For Studio, this could for example be found under: C:\Users\<your_id>\AppData\Roaming\DataFlux\DMStudio\studio1
You now have a taste of how to create reusable functions in Data Management Studio to help you both improve the quality of your data as well as improve the productivity of your data professionals. Good luck and please let us know what kind of jobs you are using to help your organization succeed.

1 Comment
Finally a UDF documentation. Very useful.