Editor’s note: This is the third in a series of articles to help current SAS programmers add SAS Viya to their analytics skillset. In this post, Advisory Solutions Architect Steven Sober explores how to accomplish distributed data management using SAS Viya. Read additional posts in the series.
In my last article I explained how SAS programmers can execute distributed DATA Step, PROC DS2, PROC FEDSQL and PROC TRANSPOSE in SAS Viya’s Cloud Analytic Services (CAS) which speeds up the process of staging data for analytics, visualizations and reporting. In this article we will explore how open source programmers can leverage the same SAS coding techniques while remaining in their comfort zone.
For this post, I will utilize Jupyter Notebook to run the Python script that is leveraging the same code we used in part one of this series.
Importing Package and Starting CAS
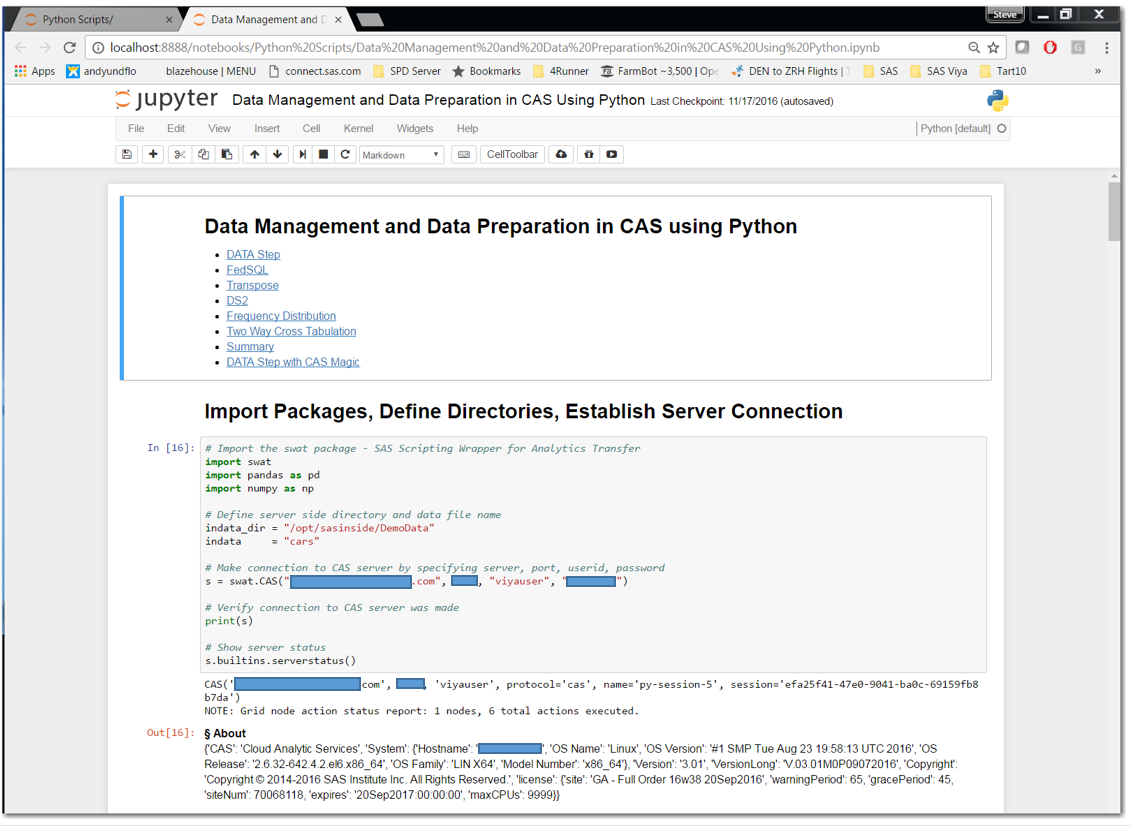
First, we import the SAS Scripting Wrapper for Analytics Transfer (SWAT) package, which is the Python client to SAS Cloud Analytic Services (CAS). To down load the SWAT package, use this url: https://github.com/sassoftware/python-swat.
Let’s review the cell “In [16]”:
1. Import SWAT
a. Required statement, this loads the SWAT package into our Python client
2. s = swat.CAS("viya.host.com", port#, "userid", "password")
a. Required statement, for our example we will use “s” in our dot notation syntax to send our statements to CAS for processing. “s” is end-user definable (i.e. I could have used “steve =” instead of “s =”).
b. Viya.host.com is the host name of your SAS Viya platform
c. Port#
i. Port number used to communicate with CAS
d. userid
i. Your user id for the SAS Viya platform
e. Password
i. Your password for your userid
3. indata_dir = "/opt/sasinside/DemoData"
a. Creating a variable call “indata_dir”. This is a directory on the SAS Viya platform where the source data for our examples is located.
4. indata = "cars"
a. Creating a variable call “indata” which contains the name of the source table we will load into CAS
Reviewing cell “Out[16]” we see the information that CAS returns to our client when we connect successfully.
Loading our Source Table and CAS Action Sets
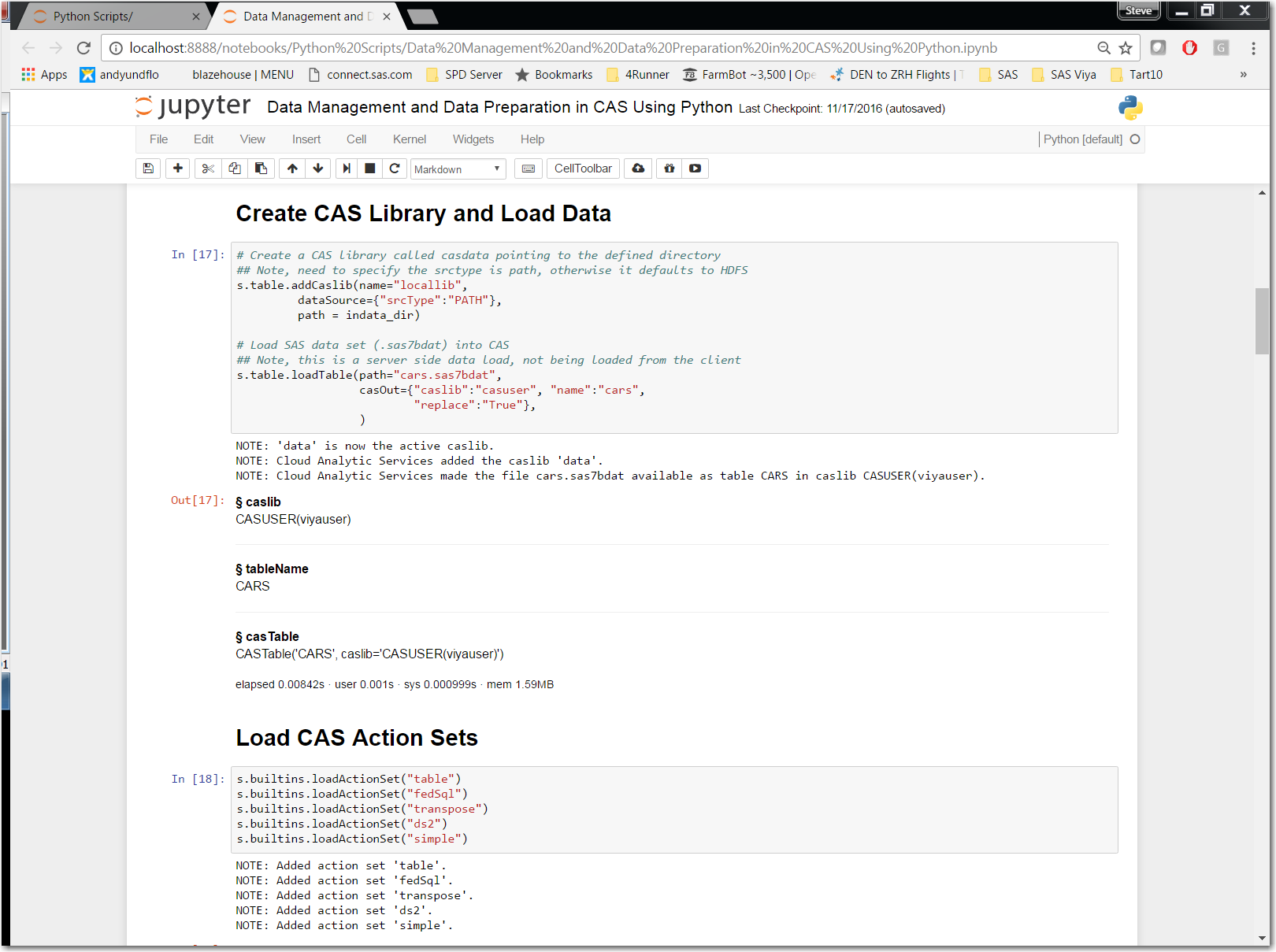
In order to load data into CAS we first need to create a CAS library and then load the source table into that CAS library. Let’s review cell “In [17]”:
1. s.table.addCaslib(name="locallib",
dataSource={"srcType":"PATH"},
path = indata_dir)
a. To send statements to CAS we use dot notation syntax where:
a. s
i. The CAS session that we established in cell “in[16]”
b. table
i. CAS action set
c. addCaslib
i. Action set’s action
d. name
i. Specifies the name of the caslib to add.
e. dataSource
i. Specifies the data source type and type-specific parameters.
f. path
i. Specifies data source-specific information. For PATH and HDFS, this is a file system path. In our example we are referencing the path using the variable “indata_dir” that we established in cell “In[16]”.
Click here for more information on the addCaslib action.
2. s.table.loadTable(path="cars.sas7bdat",
casOut={"caslib":"casuser", "name":"cars",
"replace":"True"},
)
a. As we learned s. is our connection to CAS and “table.” is the CAS action set while “Table” is the action set’s action.
a. path=
i. Specifies the file, directory or table name. In our example this is the physical name of the SAS data set being loaded into CAS.
b. casOut=
i. The CAS library we established in cell “In[17]” using the “addCaslib” action.
1 caslib.casuser
a. “caslib” - is a reserved word and is use to reference all CAS libraries
b. “casuser” - is the CAS library we will use in our examples
c. “name” - is the CAS table name
d. “replace” - provides us an option to replace the CAS table if it already exists.
Reviewing cell “Out[17]” we see the information that CAS returns to our client when we successfully load a table into CAS.
Click here for information on the loadTable action.
Reviewing cell “In[17]” we see how to load the CAS action sets we need loaded into CAS so we can leverage DATA Step, PROC DS2, PROC FEDSQL and PROC TRANSPOSE from our Python client.
Click here for information on the loadActionSet action.
DATA Step
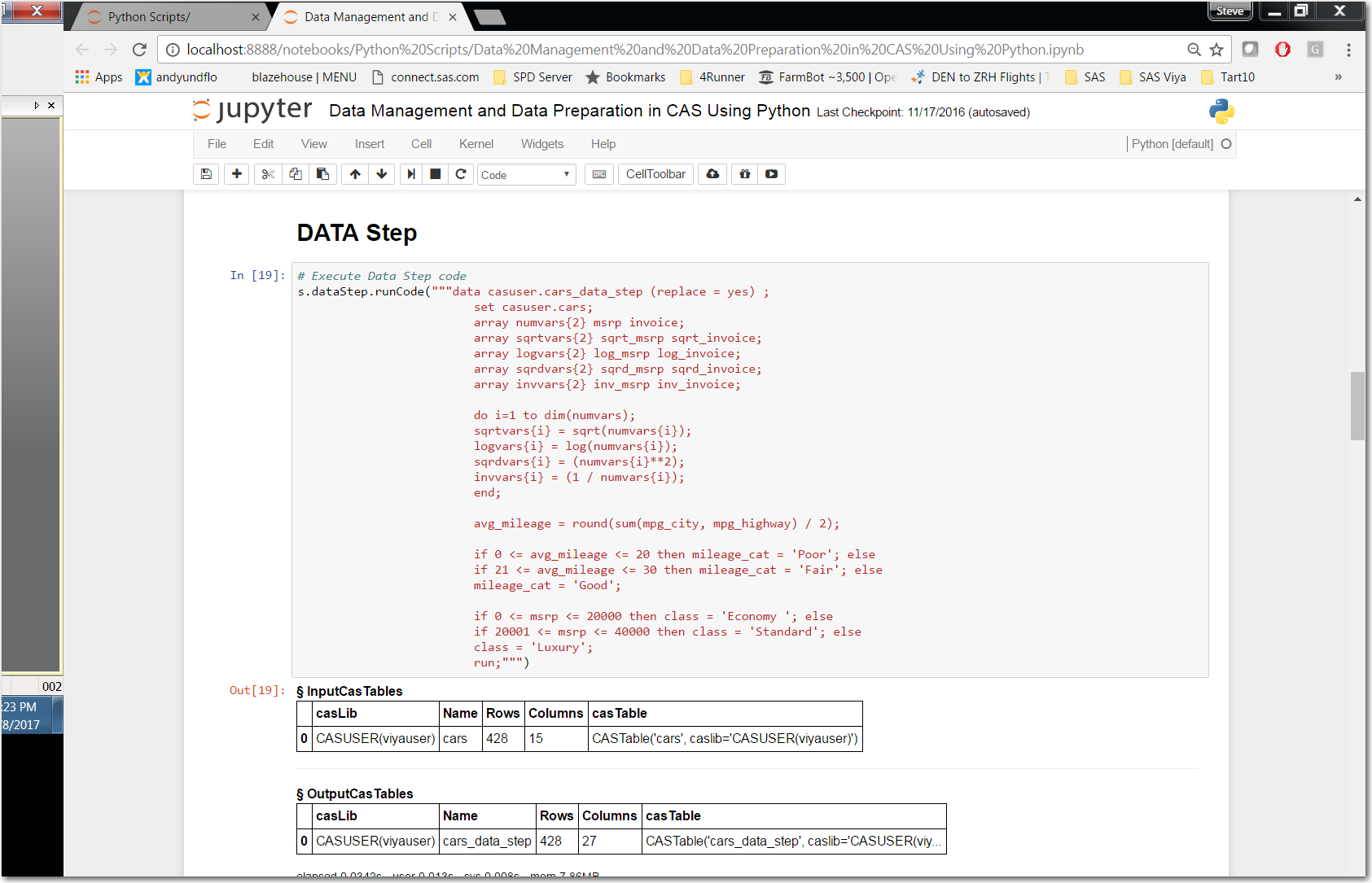
We are now ready to continue by running DATA Step, PROC DS2, PROC FEDSQL and PROC TRANSPOSE via our python script.
Now that we understand the dot notation syntax used to send statements to CAS, it become extremely simple to leverage the same code our SAS programmers are using.
Reviewing cell “In[19]” we notice we are using the CAS action set “dataStep” and it’s action “runCode”. Notice between the (“”” and “””) we have the same DATA Step code we reviewed in part one of this series. By reviewing cell “Out19]” we can review the information CAS sent back providing information on the source (casuser.cars) and target (casuser.cars_data_step) tables used in our DATA Step.
Click here for more information on the runCode action.
PROC DS2
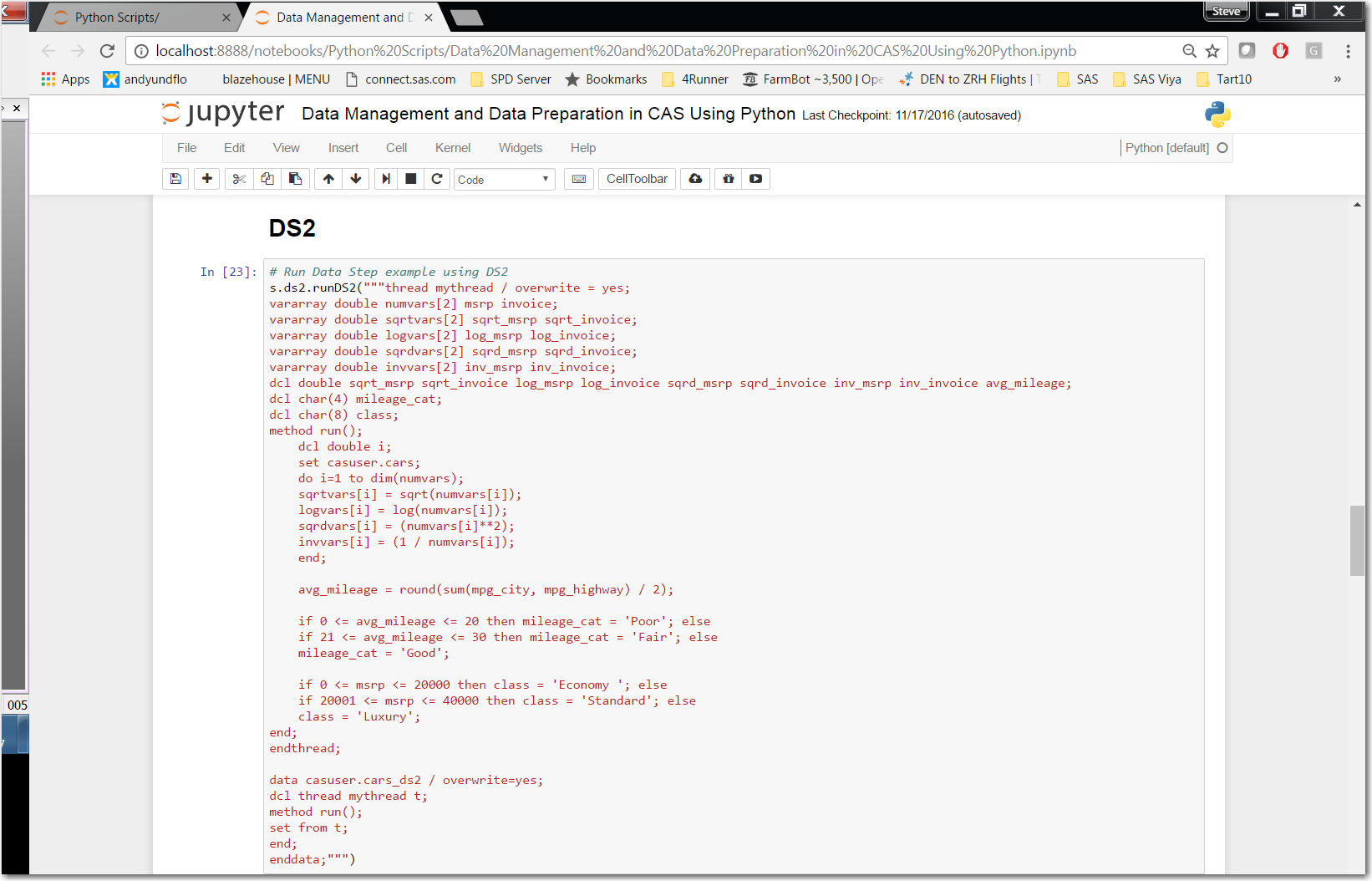
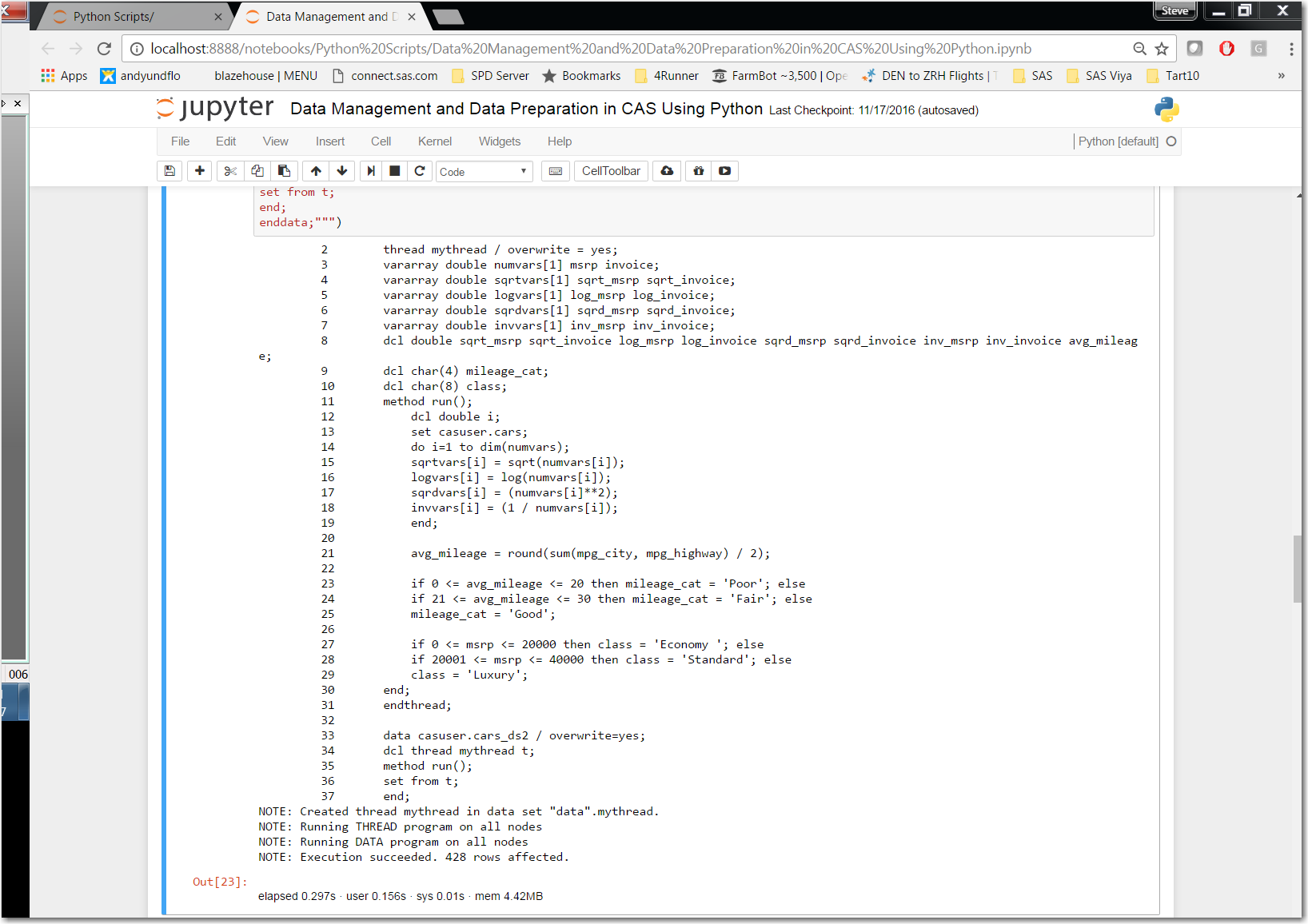
With DS2 we utilize the CAS action set “ds2” with its action “runDS2.” In reviewing cell “In[23]” we do notice a slight difference in our code. There is no “PROC DS2” prior to the “thread mythread / overwrite = yes;” statement. With the DS2 action set we simply define our DS2 THREAD program and follow that with our DS2 DATA program. Notice in the DS2 DATA program we declare the DS2 THREAD that we just created.
Review the NOTE statements: prior to “Out[23]” These statements validate the DS2 THREAD and DATA programs executed in CAS.
Click here for more information on the runDS2 action.
PROC FEDSQL
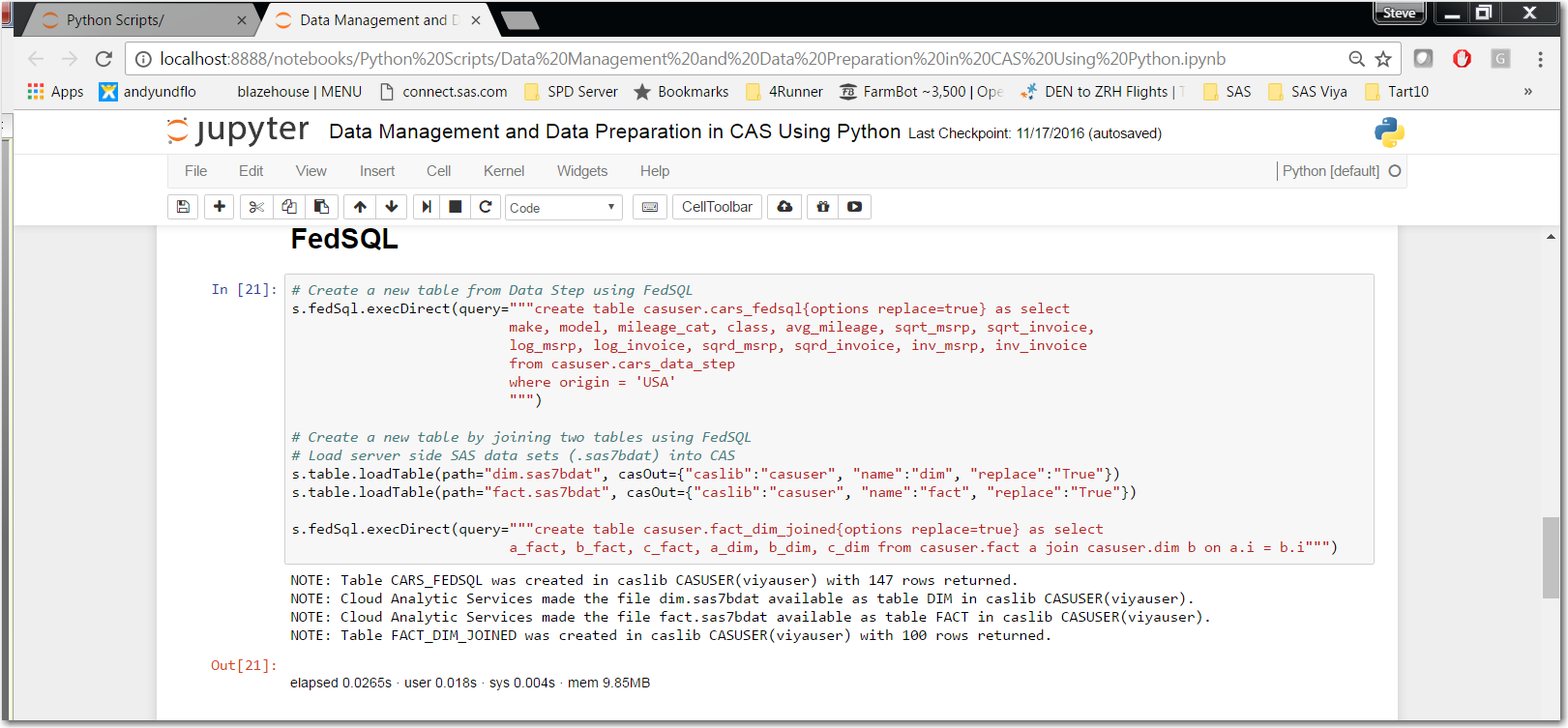
With FedSQL we use the CAS action set “fedsql’ with its action “execDirect.” The “query=” parameter is where we place our FedSQL statements. By reviewing the NOTE statements we can validate our FedSQL ran successfully.
Click here for more information on the execDirect action.
PROC TRANSPOSE
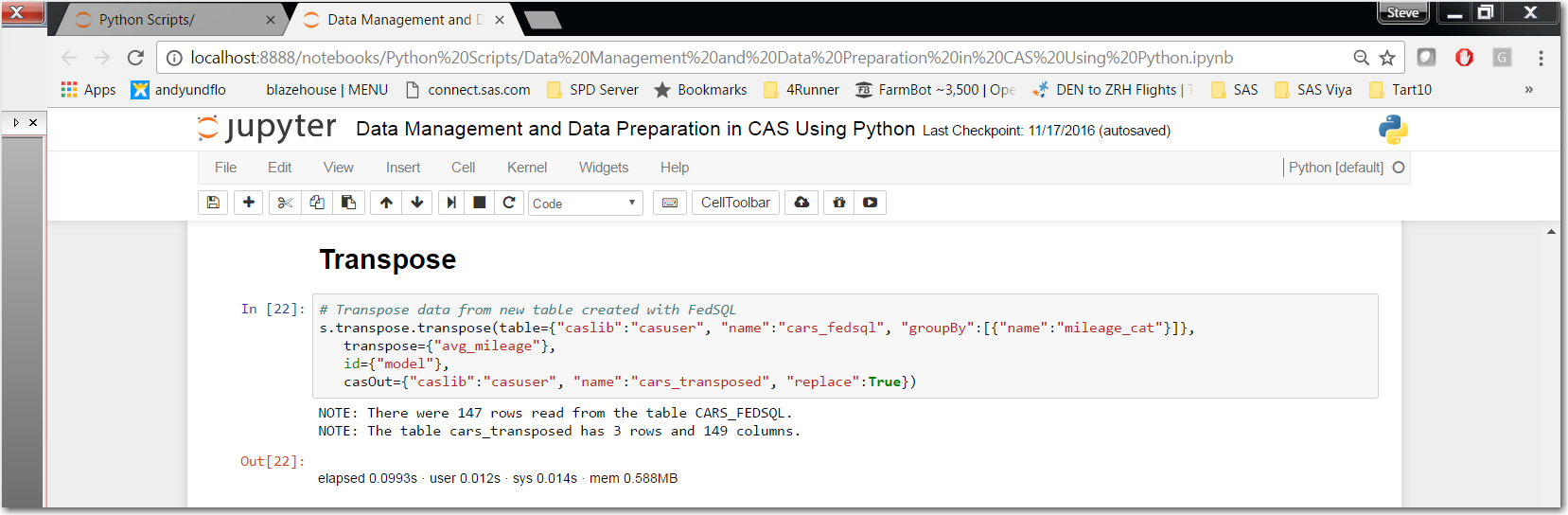
With TRANSPOSE we use the CAS action set “transpose” with its action “transpose.” The syntax is different for PROC TRANSPOSE, but it is very straight forward on mapping out the parameters to accomplish the transpose you need for your analytics, visualizations and reports.
Click here for more information on the transpose action.
Conclusion
Collaborative distributed data management means:
- SAS Viya In-Memory component CAS uses all cores on all compute nodes to speed up the processing of data (i.e. distributed data management).
- The fact SAS programmers and open source programmers can leverage the same code base means these two productive groups of programmers can collaborate on business needs (i.e. collaborative).
