 Editor’s note: This is the second in a series of articles to help current SAS programmers add SAS Viya to their analytics skillset. In this post, Advisory Solutions Architect Steven Sober explores how to accomplish distributed data management using SAS Viya. Read additional posts in the series.
Editor’s note: This is the second in a series of articles to help current SAS programmers add SAS Viya to their analytics skillset. In this post, Advisory Solutions Architect Steven Sober explores how to accomplish distributed data management using SAS Viya. Read additional posts in the series.
This article in the SAS Viya series will explore how to accomplish distributed data management using SAS Viya. In my next article, we will discuss how SAS programmers can collaborate with their open source colleagues to leverage SAS Viya for distributed data management.
Distributed Data Management
SAS Viya provides a robust, scalable, cloud ready distributed data management platform. This platform provides multiple techniques for data management that run distributive, i.e. using all cores on all compute nodes defined to the SAS Viya platform. The four techniques we will explore here are DATA Step, PROC DS2, PROC FEDSQL and PROC TRANSPOSE. With these four techniques SAS programmers and open source programmers can quickly apply complex business rules that stage data for downstream consumption, i.e., Analytics, visualizations, and reporting.
The rule for getting your code to run distributed is to ensure all source and target tables reside in the In-Memory component of SAS Viya i.e., Cloud Analytic Services (CAS).
Starting CAS
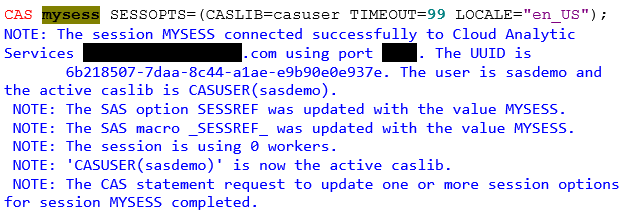
The following statement is an example of starting a new CAS session. In the coding examples that follow we will reference this session using the key word MYSESS. Also note, this CAS session is using one of the default CAS library, CASUSER.
Binding a LIBNAME to a CAS session
Now that we have started a CAS session we can bind a LIBNAME to that session using the following syntax:

Note: CASUSER is one of the default CAS libraries created when you start a CAS session. In the following coding examples we will utilize CASUSER for our source and target tables that reside in CAS.
To list all default and end-user CAS libraries, use the following statement:

Click here for more information on CAS libraries.
Click here for information on loading data into CAS.
DATA Step
The DATA Step is one of the basic building blocks of SAS programming. It is used to apply business rules to data that will be used for analysis, visualizations and reporting.
For DATA Step code to run distributed in CAS the rules are:
- All source and target tables must reside in CAS
- You must use a two level name i.e. casuser.table, when identifying your source and target tables

Click here for more information on running DATA Step in CAS.
PROC DS2
DS2 is a SAS programming language that is appropriate for advanced data manipulation. DS2 is included with Base SAS and shares core features with the SAS DATA step. DS2 exceeds the DATA step by adding variable scoping, user-defined methods, ANSI SQL data types, and user-defined packages. The DS2 SET statement accepts embedded FedSQL syntax, and the runtime-generated queries can exchange data interactively between DS2 and any supported database. This allows SQL preprocessing of input tables, which effectively combines the power of the two languages.
For PROC DS2 code to run distributed in CAS the rules are:
- All business rules to apply to the source data are defined as a DS2 THREAD program
- The PROC DS2 DATA program must declare a THREAD program
- The source and target tables must reside in CAS
- Unlike DATA Step, with PROC DS2 you use the SESSREF= parameter to identify which CAS environment the source and target tables reside in

Click here for more information on running PROC DS2 in CAS.
PROC FEDSQL
FedSQL provides a common SQL syntax across all data sources. FedSQL is a vendor-neutral SQL dialect that accesses data from various data sources without having to submit queries in the SQL dialect that is specific to the data source. In addition, a single FedSQL query can target data in several data sources and return a single result table.
For PROC FEDSQL to run in CAS the rules are:
All source and target tables must reside in CAS and you use a two level name to reference these tables
Like PROC DS2 we must identify the CAS session using the parameter SESSREF=

Click here for more information on running PROC FEDSQL in CAS.
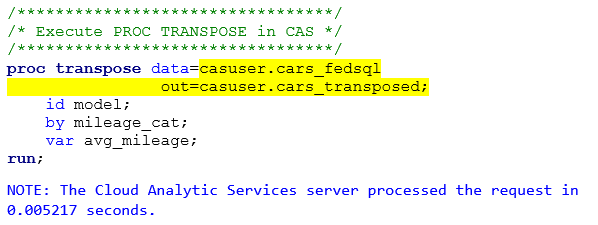
PROC TRANSPOSE
The TRANSPOSE procedure creates an output data set by restructuring the values in a SAS data set, transposing selected variables into observations. The TRANSPOSE procedure can often eliminate the need to write a lengthy DATA step to achieve the same result. Further, the output data set can be used in subsequent DATA or PROC steps for analysis, reporting or further data manipulation.
For PROC TRANSPOSE to run in CAS the rules are:
- All source and target tables must reside in CAS
a. Like DATA Step you use a two-level name to reference these tables
Click here for more information on running PROC TRANSPOSE in CAS.
Conclusion
SAS Viya allows us to stage data for downstream consumption by leveraging robust SAS programming techniques that run distributed, i.e., fast.
In my next article we will explore how these same techniques can be leveraged by our open source colleagues.
