Ensemble models have been used extensively in credit scoring applications and other areas because they are considered to be more stable and, more importantly, predict better than single classifiers (see Lessmann et al., 2015). They are also known to reduce model bias and variance (Myoung - Jong et al., 2006; Tsai C-F et. al., 2011). The objective of this article is to compare the predictive accuracy of four distinct datasets using two ensemble classifiers (Gradient boosting(GB)/Random Forest(RF)) and two single classifiers (Logistic regression(LR)/Neural Network(NN)) to determine if, in fact, ensemble models are always better. My analysis did not look into optimizing any of these algorithms or feature engineering, which are the building blocks of arriving at a good predictive model. I also decided to base my analysis on these four algorithms because they are the most widely used methods.
What is the difference between a single and an ensemble classifier?
Single classifier
Individual classifiers pursue different objectives to develop a (single) classification model. Statistical methods either estimate (+|x) directly (e.g., logistic regression), or estimate class-conditional probabilities (x|y), which they then convert into posterior probabilities using Bayes rule (e.g., discriminant analysis). Semi-parametric methods, such as NN or SVM, operate in a similar manner, but support different functional forms and require the modeller to select one specification a priori. The parameters of the resulting model are estimated using nonlinear optimization. Tree-based methods recursively partition a data set so as to separate good and bad loans through a sequence of tests (e.g., is loan amount > threshold). This produces a set of rules that facilitate assessing new loan applications. The specific covariates and threshold values to branch a node follow from minimizing indicators of node impurity such as the Gini coefficient or information gain (Baesens, et al., 2003).
Ensemble classifier
Ensemble classifiers pool the predictions of multiple base models. Much empirical and theoretical evidence has shown that model combination increases predictive accuracy (Finlay, 2011; Paleologo, et al., 2010). Ensemble learners create the base models in an independent or dependent manner. For example, the bagging algorithm derives independent base models from bootstrap samples of the original data (Breiman, 1996). Boosting algorithms, on the other hand, grow an ensemble in a dependent fashion. They iteratively add base models that are trained to avoid the errors of the current ensemble (Freund & Schapire, 1996). Several extensions of bagging and boosting have been proposed in the literature (Breiman, 2001; Friedman, 2002; Rodriguez, et al., 2006). The common denominator of homogeneous ensembles is that they develop the base models using the same classification algorithm (Lessmann et al., 2015).
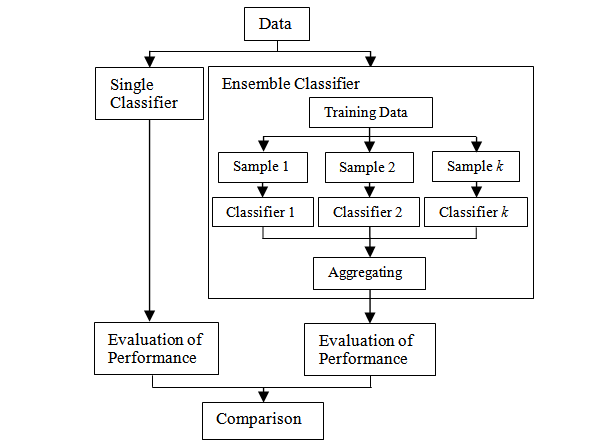
Experiment set-up
Datasets
Before modelling, I partitioned the dataset into 70% training and 30% validation dataset.
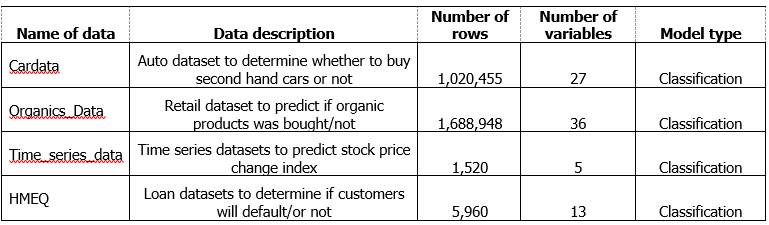
I used SAS Enterprise Miner as a modelling tool.
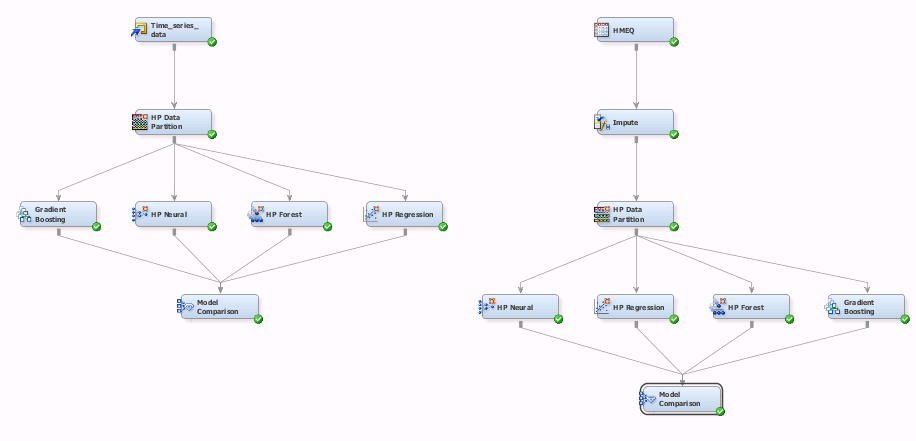
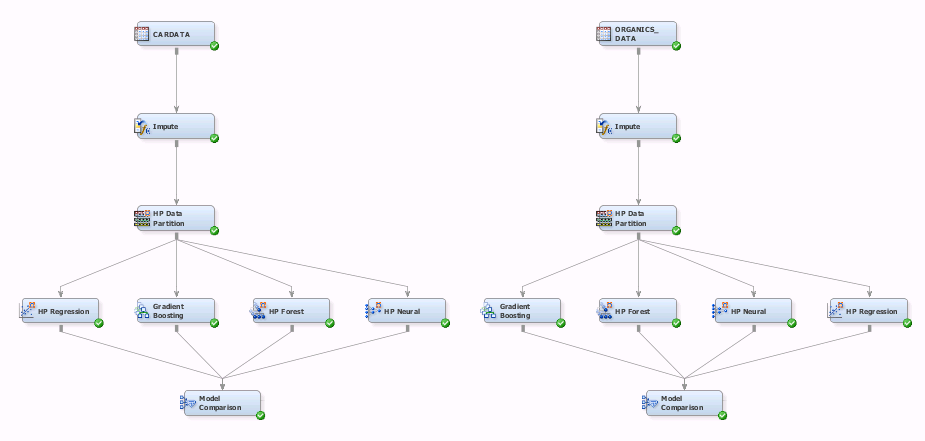
Results

Conclusion
Using misclassification rate as model performance, RF was the best model using Cardata, Organics_Data and HMEQ followed closely by NN. NN was the best model using Time_series_data and performed better than GB ensemble model using Organics_Data and Cardata.
My findings partly supports the hypothesis that ensemble models naturally do better in comparison to single classifiers, but not in all cases. NN, which is a single classifier, can be very powerful unlike most classifiers (single or ensemble) which are kernel machines and data-driven. NN can generalize from unseen data and act as universal functional approximators (Zhang, et al., 1998).
According to Kaggle CEO and Founder, Anthony Goldbloom:
“In the history of Kaggle competitions, there are only two Machine Learning approaches that win competitions: Handcrafted & Neural Networks”.
What are your thoughts?
References
Baesens, B., Van Gestel, T., Viaene, S., Stepanova, M., Suykens, J., & Vanthienen, J. (2003). Benchmarking state-of-the-art classification algorithms for credit scoring. Journal of the Operational Research Society, 54, 627-635.
Breiman, L. (1996). Bagging predictors. Machine Learning, 24, 123-140
Breiman, L. (2001). Random forests. Machine Learning, 45, 5-32.
Freund, Y., & Schapire, R. E. (1996). Experiments with a New Boosting Algorithm. In L. Saitta (Ed.), Proc. of the 13th Intern. Conf. on Machine Learning (pp. 148-156). Bari, Italy: Morgan Kaufmann.
Friedman, J. H. (2002). Stochastic gradient boosting. Computational Statistics & Data Analysis, 38, 367-378.
Finlay, S. (2011). Multiple classifier architectures and their application to credit risk assessment. European Journal of Operational Research, 210, 368-378.
Lessmann, S.,Baesens, B.,Seow, HV and Thomas, LC., (2015). Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. European Journal of Operational Research, 247 (1), 124-136
Myoung-Jong, K., Sung-Hwan, M. and Ingoo, H.(2006). An evolutionary approach to the combination of multiple classifiers to predict a stock price index. Expert Systems with Applications 31(2):241-247
Paleologo, G., Elisseeff, A., & Antonini, G. (2010). Subagging for credit scoring models. European Journal of Operational Research, 201, 490-499.
Rodriguez, J. J., Kuncheva, L. I., & Alonso, C. J. (2006). Rotation forest: A new classifier ensemble method. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28, 1619-1630.
Tsai, C.-F. , & Hsiao, Y.-C. (2011). Combining multiple feature selection methods for stock prediction: Union, intersection, and multi-intersection approaches. Decision Support Systems, 50 ,258–269
Zhang,G., Patuwo, B.E., and Hu, M.Y.,(1998). Forecasting with artificial neural networks: The state of the art. International Journal of Forecasting 14 (1998) 35–62

5 Comments
Could you please provide the full citations for the references that you cite, or link to them in the text? Thanks.
Done. Thanks
Thanks Larry for the article. It would be intereating to seensure if this behaviour extends to multinomial classification. Do ensemble models also show improved misclassification rates when classifying multiple discrete outcomes?
Thanks Larry for the article. It would be intereating to see if this behaviour extends to multinomial classification. Do ensemble models also show improved misclassification rates when classifying multiple discrete outcomes?
Thanks Graeme. I didn't consider multinomial classification in my post but I think it's worth looking into as well. Watch out for my upcoming post on this topic :).