The SAS Data Loader directive ‘Copy Data to Hadoop’ enables you to copy data from DBMS to Hadoop Hive tables.
The SAS Data Loader directive ‘Copy Data to Hadoop’ enables you to copy data from DBMS to Hadoop Hive tables.
The SAS Data Loader for Hadoop can be configured to copy data from any external database which offers JDBC database connectivity. SAS Data Loader uses the Apache Sqoop™ and Oozie components installed with the Hadoop cluster to copy data from external databases. SAS Data Loader accesses the same external database directly to display schemas and lists of tables. For this reason, the SAS Data Loader client needs the same set of JDBC drivers that are installed on the Hadoop cluster.
The SAS Data Loader directive “Copy Data to Hadoop” generates and submits Oozie workflow with Sqoop tasks to an Oozie server on the Hadoop cluster. The Ozzie workflow executes on the Hadoop cluster using MapReduce steps to copy data from the database into HDFS.
Prerequisites
- The external database-specific JDBC driver installed on the Hadoop cluster and on the SAS Data Loader client machine
- Access to Oozie and Sqoop services running on the Hadoop cluster
- A valid user ID and password to access the RDBMS database
- A valid user ID and password to access the Hadoop cluster
- The database connectors (JAR files) placed in the Sqoop lib and in the Oozie shared lib folder on HDFS
- Database connection defined for vendor-specific database under SAS Data Loader database configuration
Database connector
To connect and access external databases from a Hadoop environment, you need a vendor-specific JDBC driver. To copy data from external database to a Hadoop Hive table using Oozie and Sqoop, the database vendor’s JDBC driver (JAR file) needs to be installed on $sqoop_home/lib path folder on the Hadoop cluster and in the Oozie shared lib folder on HDFS.
For example, if you are connecting to MySQL database, you place the mySQL connector JAR file under $sqoop_home/lib path at OS and under the Oozie shared lib folder /user/oozie/share/lib/lib_20151218113109/sqoop/ on HDFS.
[root@sascdh01 lib]# pwd
/usr/lib/sqoop/lib
[root@sascdh01 lib]# ls -l mysql*
-rw-r–r– 1 root root 972009 Feb 1 15:08 mysql-connector-java-5.1.36-bin.jar
[root@sascdh01 lib]#
[root@sascdh01 ~]# hadoop fs -ls /user/oozie/share/lib/lib_20151218113109/sqoop/mysql-connector*
-rw-r–r– 3 oozie oozie 972009 2016-01-29 18:09 /user/oozie/share/lib/lib_20151218113109/sqoop/mysql-connector-java-5.1.36-bin.jar
[root@sascdh01 ~]#
The same JDBC driver on the SAS Data Loader client machine.
Example
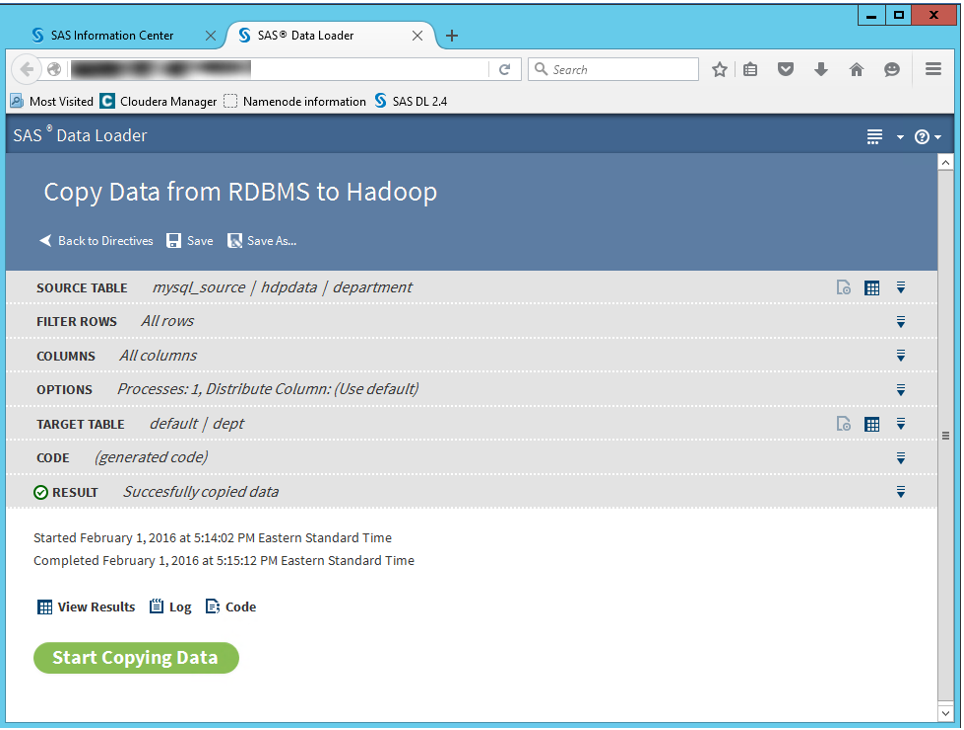
The following data loader directive example illustrates the data copy from a MySQL database table to a Hadoop Hive table. The data transfer operation executes on the Hadoop cluster using Oozie workflow and MapReduce steps. The data is streamed directly from database server to the Hadoop cluster.
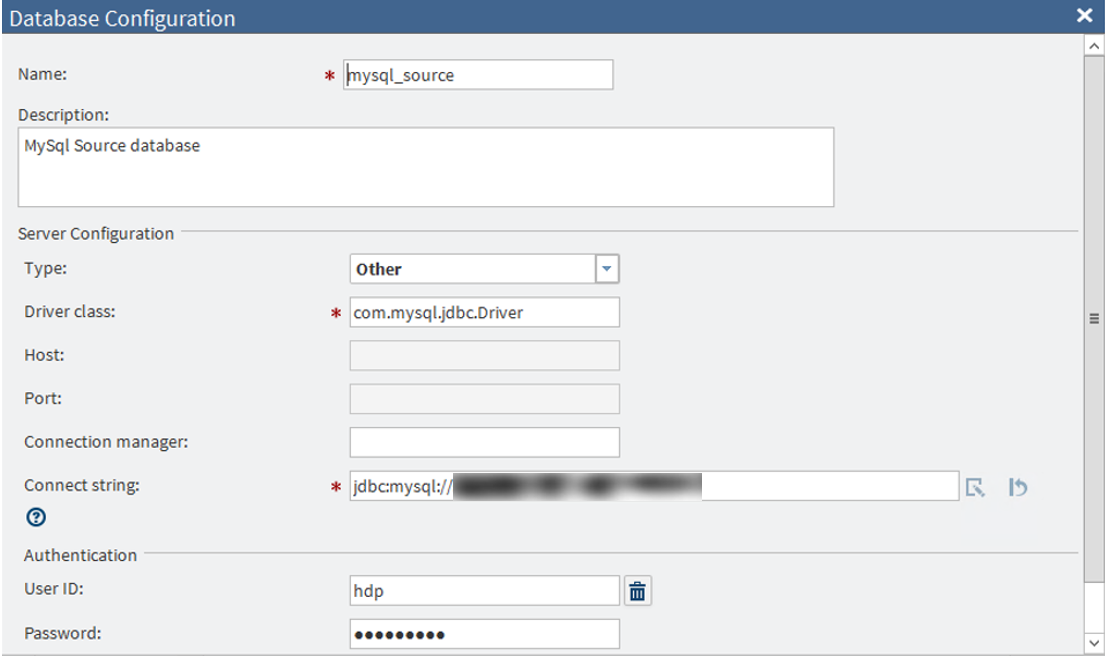
The following screen illustrates the database configuration set-up using JDBC mechanism for this example.
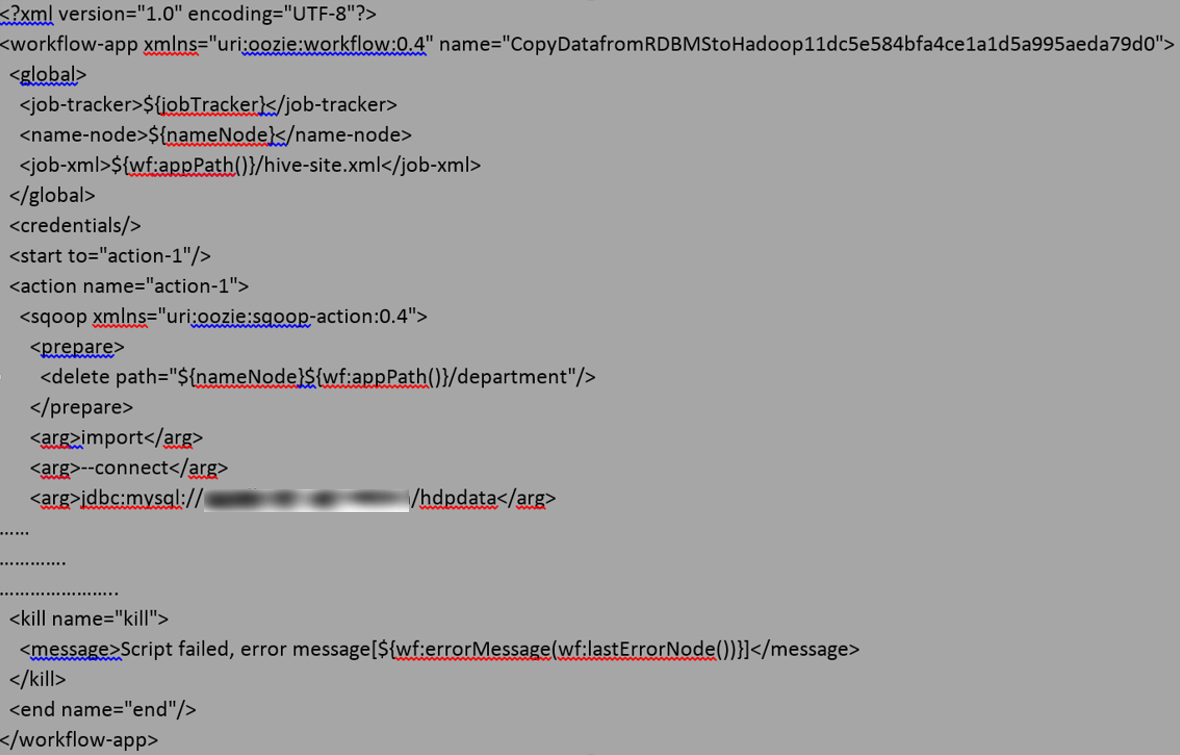
Here is a code extract from the above directive. You’ll notice it is submitting Oozie workflow to the Hadoop cluster.
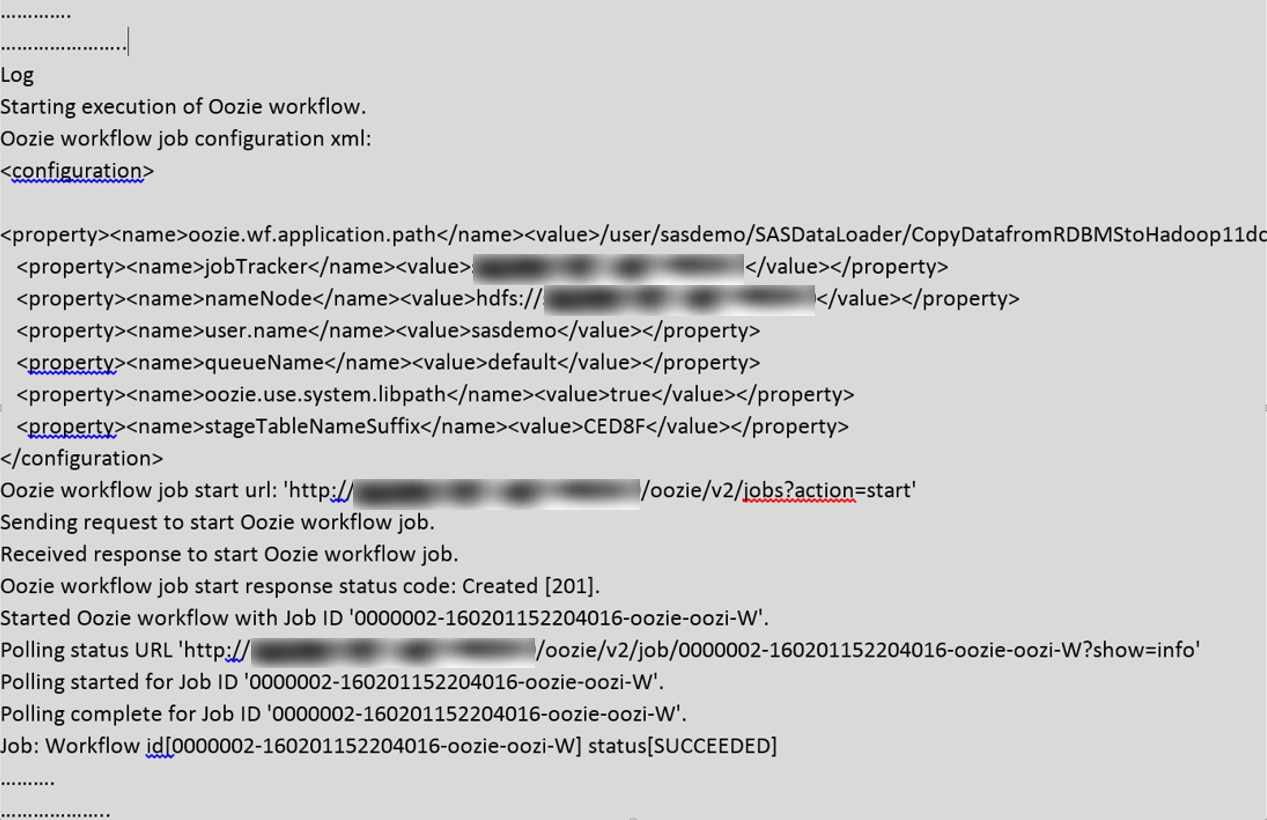
And here is the log extract from the above directive execution, showing execution of Oozie workflow:
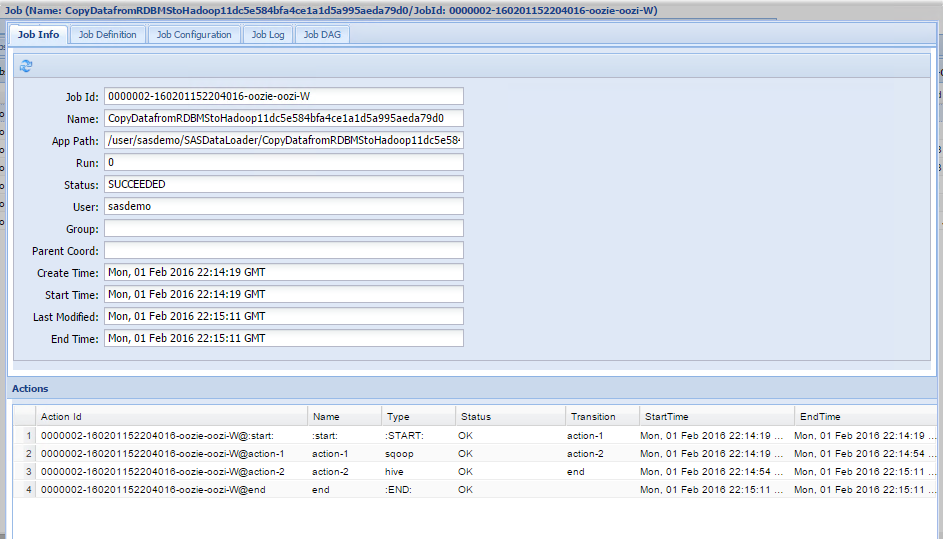
On an Oozie web console, you can see the Oozie jobs that have been submitted and their status shows either running, killed, or succeeded. By double-clicking the job ID, you can view the sequence of actions executed by the Oozie workflow.

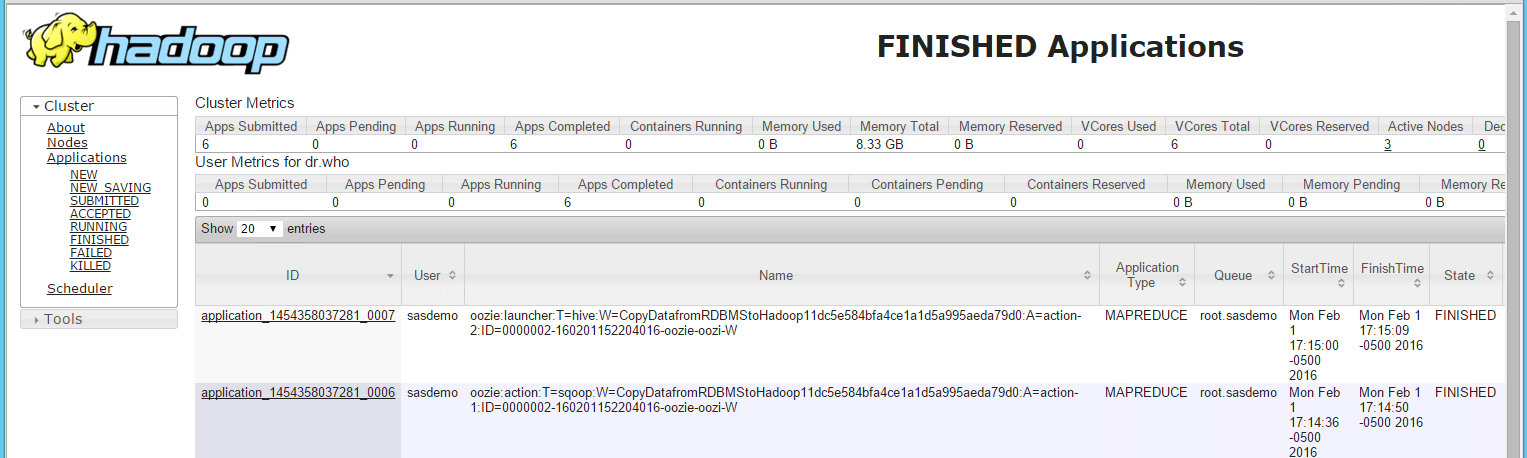
On a YARN Resource Manager user interface, you can see the MapReduce tasks that have been submitted to execute the Sqoop and Hive tasks.
On HDFS, you can see the data files that have been created per the target table mentioned in the SAS Data Loader directive.
[root@sascdh01[LL1] ~]# hadoop fs -ls /user/hive/warehouse/dept
Found 2 items
-rwxrwxrwt 3 sasdemo hadoop 22 2016-02-01 15:25 /user/hive/warehouse/dept/part-m-00000
-rwxrwxrwt 3 sasdemo hadoop 22 2016-02-01 17:14 /user/hive/warehouse/dept/part-m-00000_copy_1
[root@sascdh01 ~]#
Calling the SAS Data Loader directive using REST API
Representational State Transfer (REST) is an architectural style for designing web services that typically communicate over Hypertext Transfer Protocol (HTTP) using Uniform Resource Identifier (URI) paths. A REST application programming interface (API) is a set of routines, protocols, and tools for building software applications. A REST API is a collection of URIs, HTTP calls to those URIs, and some JSON or XML resource representations that frequently contain relational links.
The purpose of the SAS Data Loader REST API is to give scheduling systems the ability to run a SAS Data Loader directive. This API is included with SAS Data Loader and enables users to obtain a list of the existing directives and their IDs and then execute the directive without using the user interface. This API also enables users to create batch files to execute a directive and monitor the job’s state. The batch file can also be scheduled to run at specific times or intervals.
The SAS Data Loader REST API consists of the following components:
- Base URI – http://www.hostname.com/SASDataLoader/rest
- Resources – the base URI plus additional path levels that provide context for the service request, such as http://www.hostname.com/SASDataLoader/rest/customer/1234.
- HTTP methods – a call such as GET, PUT, POST, or DELETE that specifies the action.
- Representations (Media Types) – an Internet media type for the data that is a JSON or XML representation of the resource.
- Status Codes – the HTTP response code to the action.
Example
The following example illustrates the execution of a saved SAS Data Loader directive using a curl application interface. The “Sygwin with curl” application has been installed on the SAS Data Loader client machine to demonstrate this example. The saved directive name used in this example is ‘ProfileData’.
To call the SAS Data Loader directive from external application using REST API, first determine the ID of the directive and locate the URL to run the directive. The following curl statement displays information about the supplied directive name, which includes the directive ID and the URL to run.
$ curl -H "[LL1] Accept: application/json" http://192.168.180.132/SASDataLoader/rest/directives?name=ProfileData
output:
{"links":{"version":1,"links":[{"method":"GET","rel":"self","href":"http://192.168.180.132:80/SASDataLoader/rest/directives?name=ProfileData&start=0&limit=10","uri":"/directives?name=ProfileData&start=0&limit=10"}]},"name":"items","accept":"application/vnd.sas.dataloader.directive.summary+json","start":0,"count":1,"items":[{"links":[{"method":"GET","rel":"up","href":"http://192.168.180.132:80/SASDataLoader/rest/directives","uri":"/directives","type":"application/vnd.sas.collection+json"},{"method":"GET","rel":"self","href":"http://192.168.180.132:80/SASDataLoader/rest/directives/7ab97872-6537-469e-8e0b-ecce7b05c2c5","uri":"/directives/7ab97872-6537-469e-8e0b-ecce7b05c2c5","type":"application/vnd.sas.dataloader.directive+json"},{"method":"GET","rel":"alternate","href":"http://192.168.180.132:80/SASDataLoader/rest/directives/7ab97872-6537-469e-8e0b-ecce7b05c2c5","uri":"/directives/7ab97872-6537-469e-8e0b-ecce7b05c2c5","type":"application/vnd.sas.dataloader.directive.summary+json"},{"method":"POST","rel":"execute","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs?directive=7ab97872-6537-469e-8e0b-ecce7b05c2c5","uri":"/jobs?directive=7ab97872-6537-469e-8e0b-ecce7b05c2c5","type":"application/vnd.sas.dataloader.job+json"}],"version":1,"id":"7ab97872-6537-469e-8e0b-ecce7b05c2c5","name":"ProfileData","description":"Generate a profile report of the data in a table","type":"profileData","category":"dataQuality","creationTimeStamp":"2016-02-02T15:08:36.931Z","modifiedTimeStamp":"2016-02-02T15:08:36.931Z"}],"limit":10,"version":2}
$
Once the directive ID and the URL is identified, execute the saved directive using http method POST with parameters as URL to run. Once the POST statement is submitted, it displays JSON text with job ID
$ curl -H "Accept: application/json" -X POST http://192.168.180.132/SASDataLoader/rest/jobs?directive=7ab97872-6537-469e-8e0b-ecce7b05c2c5
output:
{"links":[{"method":"GET","rel":"self","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22","uri":"/jobs/22"},{"method":"DELETE","rel":"delete","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22","uri":"/jobs/22"},{"method":"GET","rel":"state","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22/state","uri":"/jobs/22/state"},{"method":"GET","rel":"code","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22/code","uri":"/jobs/22/code"},{"method":"GET","rel":"log","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22/log","uri":"/jobs/22/log"},{"method":"PUT","rel":"cancel","href":"http://192.168.180.132:80/SASDataLoader/rest/jobs/22/state?value=canceled","uri":"/jobs/22/state?value=canceled"}],"version":1,"id":"22","state":"starting","directiveName":"ProfileData","elapsedTime":0.0}
By using the job ID from the previous statement output, you can view the status of submitted job. The following statement shows the status as ”job running” and “completed” when it completes.
$ curl -H "Accept: text/plain" http://192.168.180.132/SASDataLoader/rest/jobs/22/state
output:
running
$ curl -H "Accept: text/plain" http://192.168.180.132/SASDataLoader/rest/jobs/22/state
output:
completed
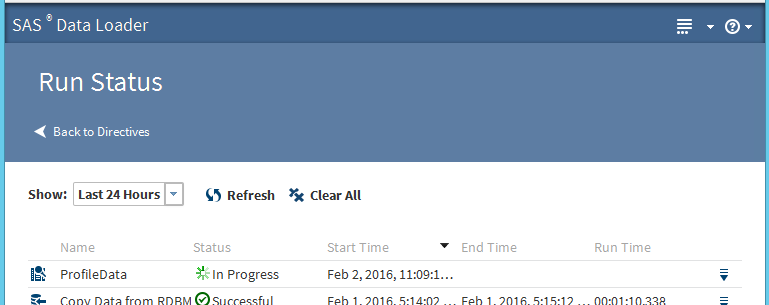
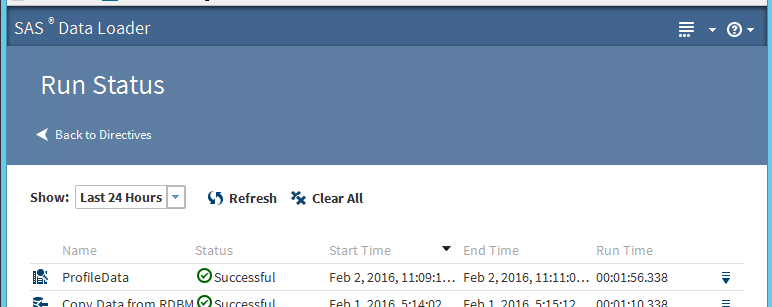
The status of the SAS Data Loader directive execution, which has been called and executed using REST API can also be viewed and monitored in the “Run Status” SAS Data Loader interface window. The following screen captures illustrate the in-progress and successfully completed jobs, which were called using REST API.