In this post I describe the important tasks of data preparation, exploration and binning.These three steps enable you to know your data well and build accurate predictive models.
In this post I describe the important tasks of data preparation, exploration and binning.These three steps enable you to know your data well and build accurate predictive models.
First you need to clean your data. Cleaning includes eliminating variables which have uneven spread across the target variable. I give an example of such a variable below. In order to detect variables of this type you can use Stat Explore and MultiPlot nodes which I cover in more detail in my book, Predictive Modeling with SAS® Enterprise Miner: Practical Solutions for Business Applications, Third Edition.
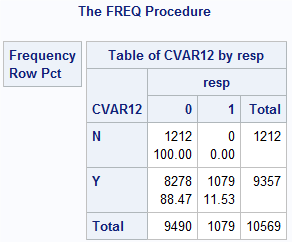
In the above display, the variable CVAR12 is a categorical input, taking the values Y and N. A look at the distribution of the variable shown in the 2x2 table suggests that it might be derived from the target variable or connected to it somehow, or it might be an input with an uneven spread across the target levels. Variables such as these can produce undesirable results, and they should be excluded from the model if their correlation with the target is truly spurious. However, there is also the possibility that this variable has valuable information for predicting the target. Clearly, only a modeler who knows where his data came from, how the data were constructed, and what each variable represents in terms of the characteristics and behaviors of customers will be able to detect spurious correlations. As a precaution before applying the modeling tool, you should examine every variable included in the final model (at a minimum) for this type of problem.
Finally, in predictive modeling, binning can be used to achieve smooth distributions across target variables. SAS Interactive binning can be used to combine or split the bins to make the relation between the target variable and levels of the bins follows a smooth pattern. The Interactive Binning node saves these bin definitions and appends them to the data sets that it passes to the next node. You can save the data set created by the Interactive Binning node, and construct new variables from the bins. In my book, I show how to combine or split the bins using the Interactive Binning Node.
It is also important that the data used in developing a predictive model is consistent with the data used for implementing the predictive model. In my next post I illustrate the data set requirements for developing a model that is used to predict attrition in a future periods.