Die Geburtenrate in Deutschland befindet sich derzeit auf dem höchsten Niveau seit 33 Jahren. Eine erfreuliche Entwicklung, und zugleich stellt es Eltern vor die schwere Entscheidung, welchen Namen der Nachwuchs tragen soll. Zahlreiche Webseiten und Bücher bieten Hitlisten und Namensbeschreibungen an, um die Auswahl zu erleichtern. Oder sollte man das Thema analytisch-visuell angehen? Hier mein Versuch mit SAS Visual Analytics.
Zuerst einmal braucht man wie immer eine gute Datengrundlage, um überhaupt loslegen zu können. Da ich keine Hitlisten von Webseiten abtippen oder mich auf das dünne Eis des Urheberrechts begeben wollte, habe ich die Vornamenstatistik der Stadt Frankfurt herangezogen. Diese Daten stehen unter www.offenedaten.frankfurt.de als Open Data für jedermann zur Verfügung. Man bekommt für die Jahre 2000 bis 2017 jeweils die Top 30 Jungen- und Mädchennamen und deren absolute Häufigkeit in den jeweiligen Jahren.

Grafik 1: Ursprünglicher Datensatz
Das ist erstmal nicht viel. Aber es lassen sich aus diesen Daten einige Dinge ableiten. Zuerst natürlich der Zeitbezug. Reiht man die einzelnen Jahre aneinander, bekommt man eine Zeitreihe von 16,5 Jahren (2017 steht bis 30.06.17 zur Verfügung). Das ist die zentrale Grundlage, um Verläufe und Trends ableiten zu können. Dann habe ich die Namen selbst zerpflückt, indem ich die Länge (Anzahl der Buchstaben) und das Vorkommen der Vokale in den Namen abgeleitet habe. Ich hatte die Vermutung, dass die Namen immer kürzer werden und es eine deutliche „A-Zunahme“ gibt – also der Buchstabe „A“ immer häufiger verwendet wird.

Grafik 2: Erweiterter Datensatz
Evergreens und One-Hit-Wonder
Um ein Gefühl für die Daten zu entwickeln, habe ich natürlich ein paar deskriptive Statistiken erstellt und konnte somit die Mengenverhältnisse genauer betrachten. In Grafik 3 sieht man, schön nach klassischen Farben getrennt, die häufigsten Mädchen- und Jungennamen der letzten 16,5 Jahre. Der Name Marie wurde z. B. in 3.336 Fällen vergeben, bei den Jungs war es 2.556 Mal ein Alexander.
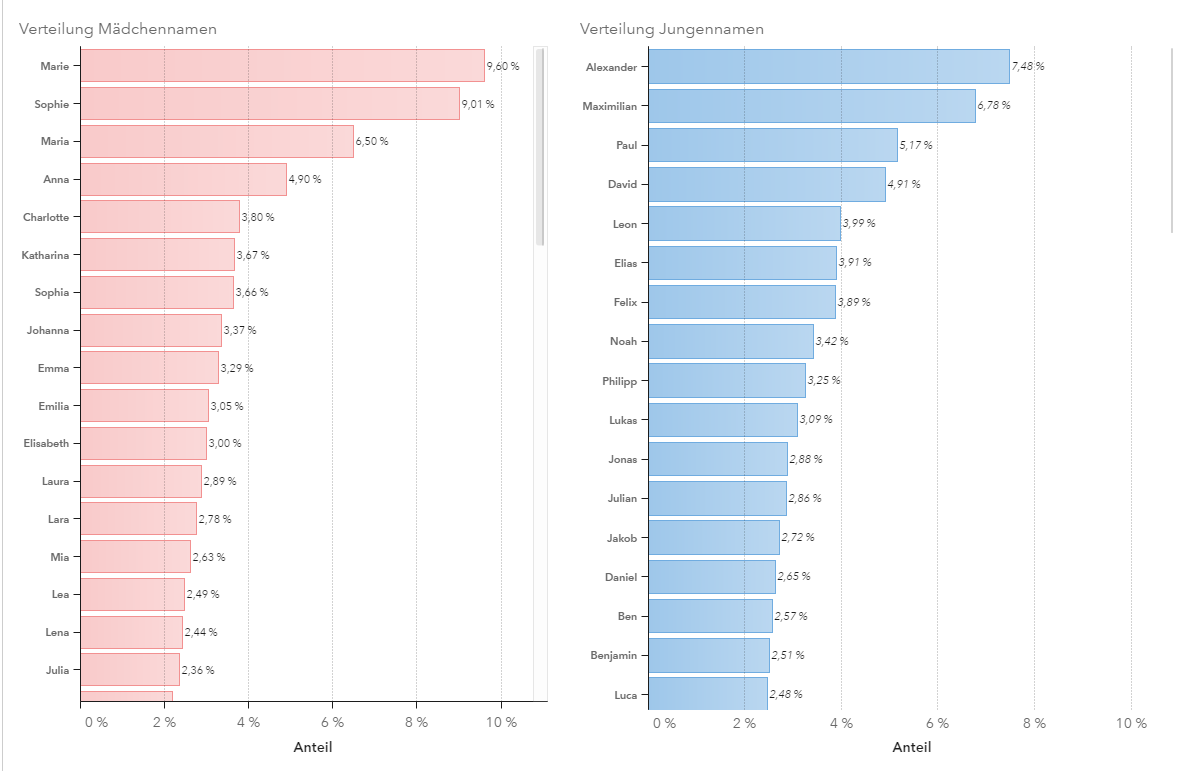
Grafik 3: Häufigkeiten der Namen nach Mädchen und Jungen
Aber es gibt auch Namen, die es in den letzten fast 17 Jahren nur einmal in die Top 30 geschafft haben, wie etwa Maja, Selina, Peter oder Carl. Wer also etwas individuellere, aber nicht völlig exotische Vorstellungen hat, ist mit den One-Hit-Wonders ganz gut beraten.
Trends und Forecasts
Neben diesen beschreibenden Statistiken habe ich mich zudem auch für Zeitreihenanalysen, Trends und Forecasts interessiert. Also die Fragen, welche Namen haben in den letzten Jahren die größten Zuwachsraten gehabt und welche sind auf einem absteigenden Ast. Insgesamt sind es über 100 einzelne Namen, die mehr oder weniger eine Datenhistorie aufweisen können. Visuell ist ein Trend auf den ersten Blick nicht so einfach zu erfassen, wie die nachfolgende Grafik zeigt.

Grafik 4: Alle Namen im Verlauf
Also habe ich Cluster gebildet, die automatisch die Namen mit den höchsten Zuwachsraten und den größten Verlusten zeigen, und natürlich für diverse Zeitabschnitte – also für die letzten fünf, zehn und 16 Jahre.
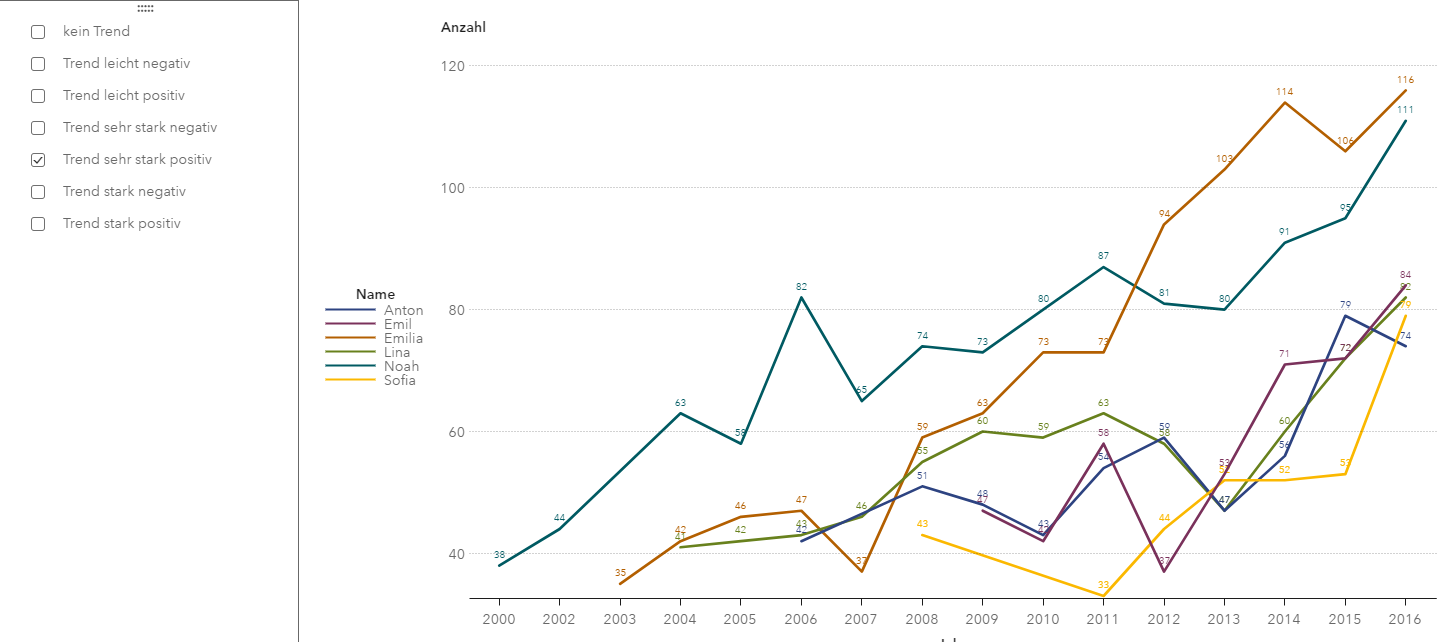
Grafik 5: Namen mit dem stärksten positiven Zuwachs über 16 Jahre
Hier war dann deutlich zu sehen, dass z. B. Emilia wie Phönix aus der Asche von 35 auf 116 geklettert war. Auf der anderen Seite war Daniel der Name mit den meisten Verlusten im selben Zeitraum. Als nächsten Schritt in meiner Analyse habe ich dann für beide Namen noch einen Forecast für die nächsten zwei Jahre rechnen lassen. Mein Forecast für Emilia zeigt für das Jahr 2017 122 Nennungen an. Durchaus realistisch, denn bis zum 30.06. gab es in Frankfurt bereits über 50 Emilias.

Grafik 6: Forecast Emilia und Daniel
In der Kürze liegt die Würze
Kommen wir zum dritten und letzten Teil meiner Analyse. Ich hatte ja eingangs die These aufgestellt, dass die Namen in den letzten Jahren immer kürzer wurden und dass der Buchstabe „A“ ebenfalls an Bedeutung zugenommen hat. Dazu habe ich die Länge der Namen und die Anzahl der „A“ aus den Daten abgeleitet. Und siehe da – im Schnitt waren die Namen im Jahr 2000 5,8 Buchstaben lang und heute liegen wir bei 5,5. Bei Mädchennamen ist der Trend sogar noch deutlicher: von 5,8 auf 5,3.
Nur das mit den „A“ lässt sich weder für Jungen- noch für Mädchennamen bestätigen. Im Vergleich ist der „A“-Anteil bei Mädchen höher, das liegt wohl sehr stark an den Annas und Hannas.

Grafik 7: Verlauf der Namenlänge und Vokale
Fazit
Ob die Ergebnisse meiner Analyse Ihnen am Ende den entscheidenden Impuls bei der Namenswahl geben, lasse ich mal offen. Das Thema ist natürlich sehr emotional behaftet und jeder hat so seine eigenen Auswahlkriterien. Trotzdem muss man sagen, es gibt mit den nackten Zahlen doch die eine oder andere Erkenntnis und Bestätigung eines Bauchgefühls – z. B. bei der Namenslänge.
Es zeigt aber auch, was man aus einer vermeintlich kleinen Datenquelle mit nur drei Spalten alles ableiten und herausfinden kann, wenn man das richtige Werkzeug zur Hand hat. Sollten Sie noch weitere Ideen zum Thema haben, melden Sie sich bei mir.






