 Mal ehrlich, wenn ich Sie fragen würde, worüber die Kandidaten im diesjährigen US-Wahlkampf in ihren Aufeinandertreffen debattiert haben – welche Kernthemen würden Sie mir spontan (abseits von Skandalen und Affären) nennen? Und könnten Sie diese Kernthemen den einzelnen Kandidaten zuordnen? Als ich mir diese Frage stellte, war die Antwort – sprich die Liste an Themen, an die ich mich tatsächlich erinnere – frustrierend kurz. Glücklicherweise bietet die Textanalytics Verfahren, um sich schnell einen Überblick über relevante Themen in einer Sammlung von Texten zu verschaffen. Lassen Sie uns mit SAS Contextual Analysis herausfinden, worüber in den TV-Duellen des US-Wahlkampfes debattiert wurde.
Mal ehrlich, wenn ich Sie fragen würde, worüber die Kandidaten im diesjährigen US-Wahlkampf in ihren Aufeinandertreffen debattiert haben – welche Kernthemen würden Sie mir spontan (abseits von Skandalen und Affären) nennen? Und könnten Sie diese Kernthemen den einzelnen Kandidaten zuordnen? Als ich mir diese Frage stellte, war die Antwort – sprich die Liste an Themen, an die ich mich tatsächlich erinnere – frustrierend kurz. Glücklicherweise bietet die Textanalytics Verfahren, um sich schnell einen Überblick über relevante Themen in einer Sammlung von Texten zu verschaffen. Lassen Sie uns mit SAS Contextual Analysis herausfinden, worüber in den TV-Duellen des US-Wahlkampfes debattiert wurde.
Von Dokumenten zu Termen
Für Text-Mining-Analysen werden in SAS Contextual Analysis Freitexte (1) mittels Natural Language Processing automatisch in eine Dokument-Term-Matrix überführt, die Häufigkeiten von Termen und ihren Synonymen (Flektionen, Rechtschreibfehler, hinterlegte Synonymbeziehungen) beinhaltet. Die dazu angewandten Verfahren des Natural Language Processing umfassen unter anderem die:
- Zerlegung eines Dokuments in einzelne Bausteine (Tokenisierung)
- Erkennung von Wortgruppen (z. B. United States of America)
- Zuordnung einer Wortklasse (z. B. Nomen, Adjektiv, …)
- Erkennung von natürlichen Entitäten (z. B. Person, Unternehmen, Ort, Datum, Uhrzeit, …)
- Rückführung auf den Wortstamm (Lemmatisierung)
- Erkennung von Rechtschreibfehlern
- …
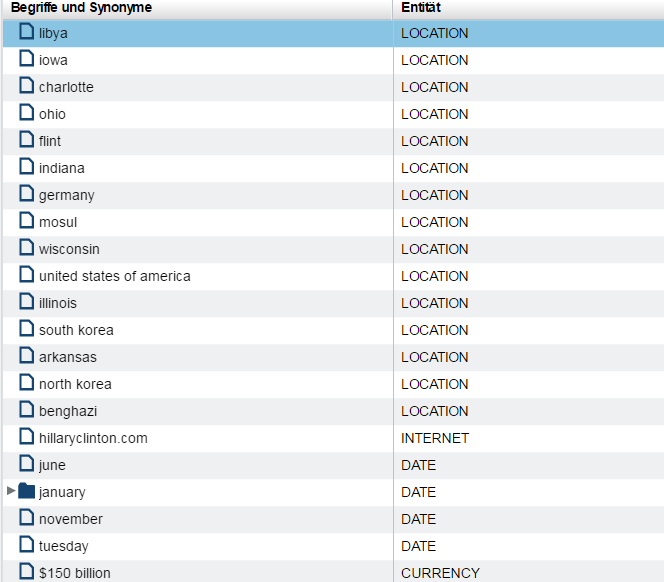
Abbildung 1: Extrahierte Entitäten
Exploration
Wie können nun die Inhalte der Debatten analysiert werden? Mittels Assoziations-Diagrammen lassen sich Assoziationen zwischen Termen darstellen. Das unten dargestellte Diagramm offenbart beispielsweise, dass die relative Häufigkeit des Terms „Syria“ im Kontext der Kombination „ISIS + threat“ hoch ist, was Hinweise auf ein bestimmtes Thema gibt. Die anderen Term-Maps zeigen mögliche Themen im Zusammenhang mit der Gesundheitsreform beziehungsweise rund um den Begriff „Wirtschaft“.
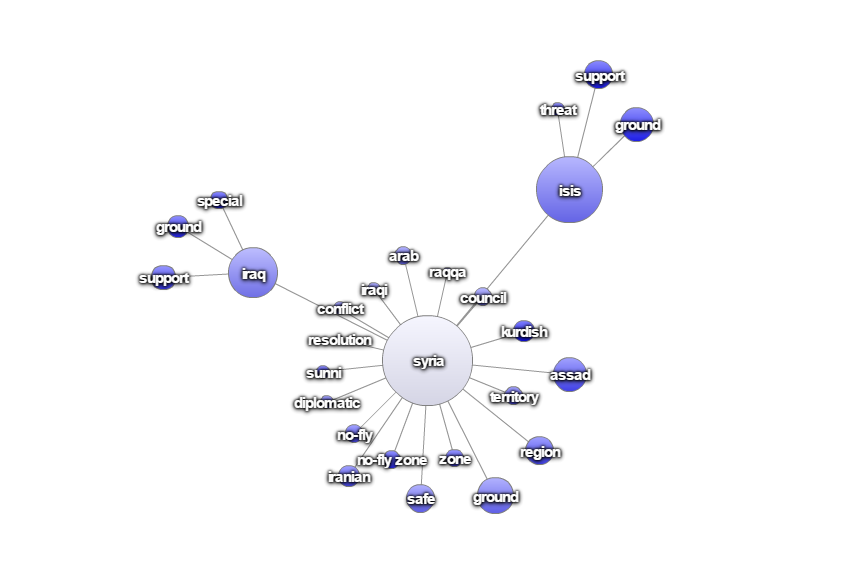
Abbildung 2: „Syria"
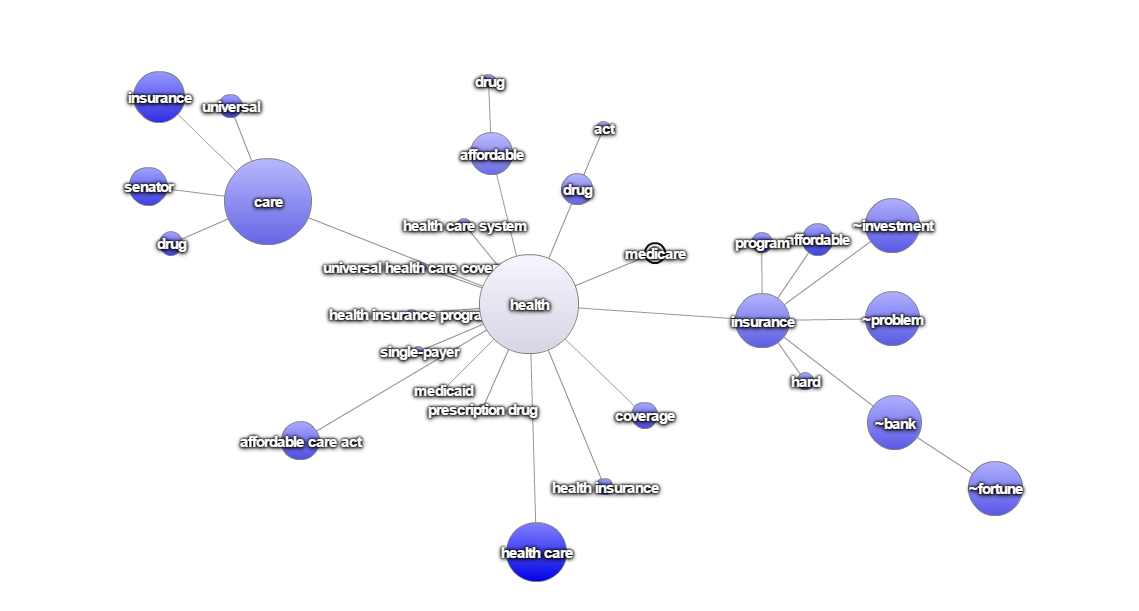
Abbildung 3: „Health"
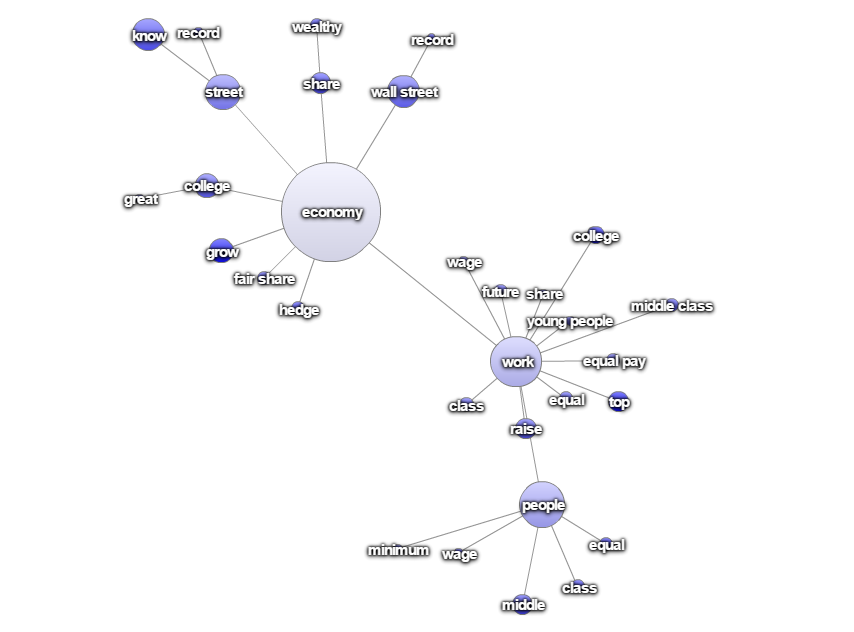
Abbildung 4: „Economy"
Von Termen zu Themen
Wie entstehen aus Termen Themen? Der Algorithmus zur Identifikation von Themen basiert auf dem dimensionsreduzierenden Verfahren der Singulärwert-Zerlegung (SVD) sowie einer Rotation (VARIMAX oder PROMAX) (https://blogs.sas.com/content/sascom/2015/10/22/topical-advice-about-topics-comparing-two-topic-generation-methods/). In Analogie zur Faktorenanalyse aus der multivariaten Statistik werden dabei aus einer hochdimensionalen Term-Dokument-Matrix wenige latente Faktoren („Themen“) abgeleitet. Im Unterschied zum Clustering kann ein Dokument eines, keines oder mehrere Themen enthalten.
Was waren also die diskutierten Themen? Die folgende Tabelle stellt Themen mit ihren beschreibenden Termen dar. Es finden sich unter anderem „ISIS und Syrien“, „Reform des Gesundheitssystems“, „Einwanderungsgesetze“, „Waffengesetze“ und „Steuergesetze“.
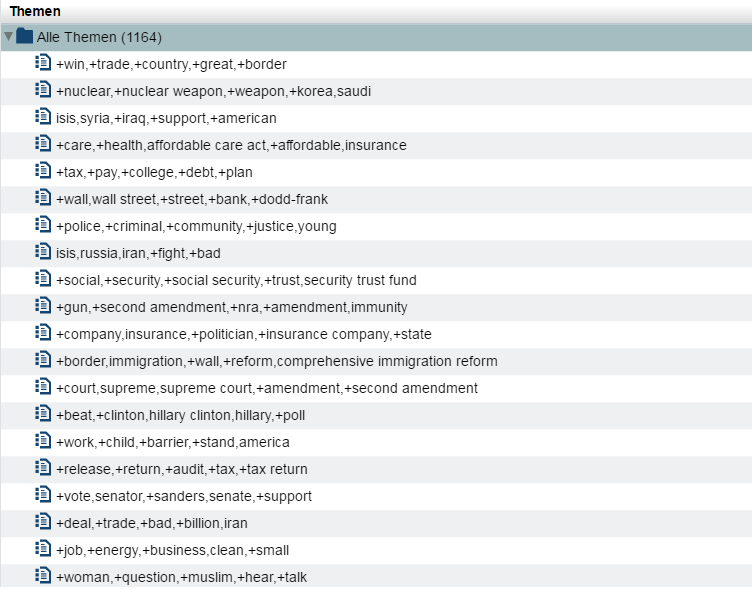
Abbildung 5: Themen
Und worüber haben die beiden Kandidaten, separat betrachtet, gesprochen? Können Sie die folgenden Listen an Themen den einzelnen Kandidaten zuordnen?
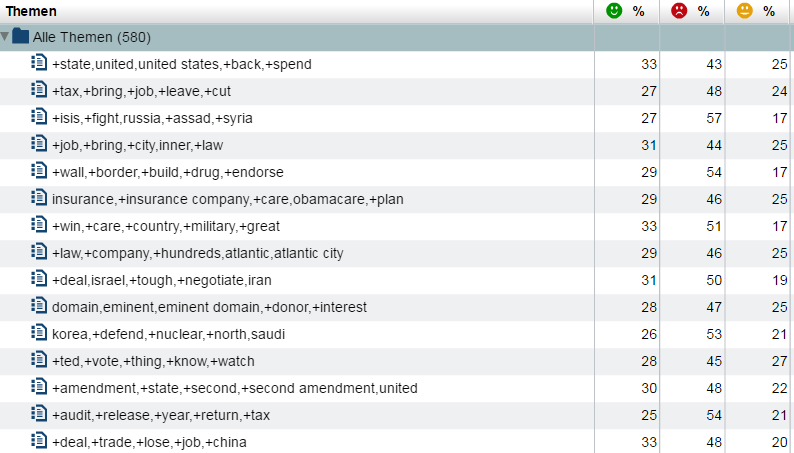
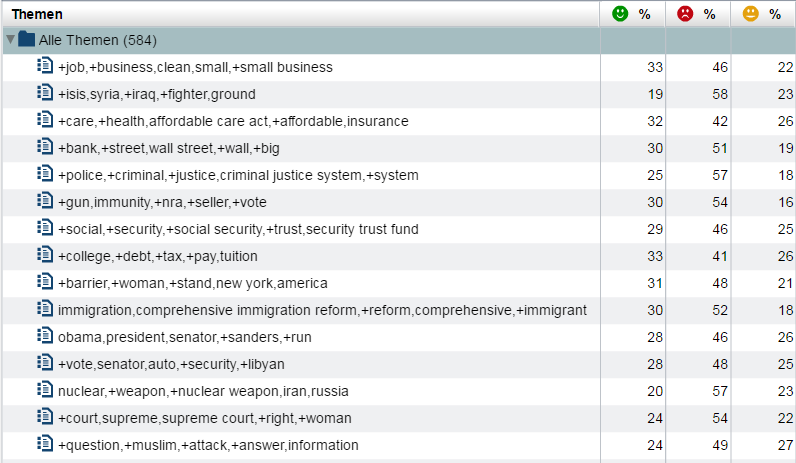
Abbildung 6: Themen der Kandidaten
Von Explorativ zu Prädiktiv
Analytisch lässt sich die Identifikation von Themen in den Bereich der nicht überwachten („unsupervised“) Verfahren einordnen. Wie die vorherigen Darstellungen jedoch zeigen, lassen sich den beiden Kandidaten verschiedene Themen zuordnen. In Teil 2 dieser Blogserie möchte ich zeigen, wie einmal identifizierte Themen als Prädiktoren in Machine-Learning-Verfahren verwendet werden können, um Texte zu kategorisieren. Wie verlässlich kann der Algorithmus zuordnen, welche Wortbeiträge von welchem Kandidaten sind?
(1) --------
Die Webseite http://www.presidency.ucsb.edu/debates.php stellt Transkripte der Presidential Debates sowie der Presidential Candidate Debates der Demokraten und Republikaner zur Verfügung. Mit dem SAS CRAWLER und BASE SAS Mitteln lassen sich diese Transkripte in eine Tabelle überführen, in der die Wortmeldung eines Kandidaten oder Moderators in einem Datensatz abgebildet wird. Für die folgende Analyse wurden alle Wortmeldungen der beiden Präsidentschaftskandidaten in den Presidential Debates und Presidential Candidate Debates verwendet, die mehr als zehn Wörter umfassen.
