Black or White Box?
Bei der Bewertung der Güte von Modellen im Rahmen von Predictive Modeling liegt der Fokus heute häufig auf der Prognosegenauigkeit. Mit anderen Wort: Wie gut ist das jeweils gewählte Modell in der Lage, das tatsächlich eingetretene interessierende Ereignis oder den Wert der Zielvariablen vorzusagen. Verschiedene Gütekriterien haben sich dafür in der Modellierungspraxis etabliert. Je nach Fragestellung und Ausprägung der Zielgröße werden beispielsweise eines oder mehrere der folgenden Kriterien herangezogen:
- Fehlklassifikationsrate
- (Kumulierter) Lift
- Gini oder ROC
- Information Gain
- R Quadrat
- mittlerer Quadratischer Fehler oder Root Mean Squared Error (RMSE)
- Akaike Informationskriterium
- Kolmogorov-Smirnov-Statistik
- Mean Absolute Percent Error (MAPE)
Aus dem Trainingsdatenbestand wird dazu meist ein Teil der Daten für die eigentliche Modellanpassung herausgehalten und als Testmenge (mitunter auch als Validierungs- oder Holdout-Sample bezeichnet) für die Bewertung herangezogen. Man simuliert also quasi, wie sich das Modell verhält, wenn es mit neuen Daten konfrontiert wird. Dieses Vorgehen hat sich in der Praxis bewährt, um sogenanntes Over-Fitting zu vermeiden, also das Lernen der Eigenheiten der jeweiligen Trainingsstichprobe—ohne die Fähigkeit zu generalisieren.
Nun gibt es verschiedene Arten von Prognosealgorithmen, mit denen man eine gute Prognosegüte erreichen kann. Sofern dieses Kriterium allein dominiert und man über eine gewissenhafte Validierung des Modells out-of-sample seine Robustheit sicherstellt, ist die Entscheidung bzgl. eines bestimmten Algorithmus zunächst mal irrelevant.
Wenn ich bei Kundengesprächen in der Praxis bzgl. der verwendeten Modelle und Algorithmen nachfrage, stelle ich häufig fest, dass auch die Frage interessiert, inwieweit sich die Ergebnisse des Algorithmus nachvollziehen lassen. Mit anderen Worten: Handelt es sich eher um eine „Black Box“ oder um ein transparentes Modell? Die in der Praxis verbreiteten Algorithmen schneiden nach diesen Kriterien sehr unterschiedlich ab.
Auf der einen Seite stehen Verfahren aus der künstlichen Intelligenz und dem maschinellen Lernen, wie z.B. neuronale Netze oder Support Vector Machines. Deren Transparenz ist vergleichsweise gering, wenngleich man sie nicht wirklich als „Black Box“ bezeichnen kann. Schließlich werden sie schon lange in der wissenschaftlichen Literatur behandelt, ihre Anwendbarkeit und ihre Stärken und Schwächen sind weitgehend erforscht. Sie haben häufig bzgl. der Prognosegenauigkeit hohes Potenzial, weil sie sehr flexibel mit Nichtlinearitäten und schwachen Signalen in den Daten umgehen können. Man muss nur wissen, wie man sie geeignet trainiert. Sie sind nur insofern intransparent, als man die Art und Weise, wie der jeweilige Algorithmus zu seinen Prognoseergebnissen kommt eben nicht in einer einfachen Formel als Linearkombination von Summanden oder in Form von Wenn-Dann-Regeln eines Entscheidungsbaums beschreiben kann.
Auf der anderen Seite stehen lineare oder verallgemeinerte Modelle, die aus dem Umfeld der Statistik kommen und bei denen häufig bestimmte Wahrscheinlichkeitsverteilungen und Modellannahmen unterstellt werden. Hier muss man häufig im Vergleich zu Verfahren des maschinellen Lernens Abstriche an der Flexibilität machen. Dafür „gewinnt“ man aber auch etwas - nämlich Transparenz. In solchen Modellen lassen sich die Effekte einzelner Input-Merkmale oder Features auf die Zielgröße konkret anhand von Regressionskoeffizienten messen. Das Modell lässt sich über eine einzige – wenn auch vielleicht komplexe – Formel beschreiben. Insofern bietet Transparenz einige Vorteile und Nutzen:
- Die Ergebnisse lassen sich leichter intern und extern „politisch verkaufen“. Man denke beispielsweise an Situationen, wie die Entscheidung über die Ablehnung eines Kreditantrags einem Kunden transparent gemacht werden muss.
- Auch Nicht-Experten können sich schneller in die Modelldetails einarbeiten bzw. es gibt eine breitere Basis von Personen, die die Modellbildung in die richtige Richtung steuern können, wenn es gilt, die Güte eines schlechter werdenden Modells zu verbessern.
- Da Modellbildung häufig ein iterativer Prozess ist, besteht meist ein Interesse daran, selbst zu verstehen, wie sich ein Modell unter bestimmten Konstellationen verhält und daraus Rückschlüsse für zukünftige Modellierungsstrategien zu ziehen. Das Studium der entsprechenden Literatur reicht dazu allein nicht aus.
Häufig fällt die Entscheidung zugunsten der Transparenz, selbst wenn man dafür Abstriche an der Genauigkeit in Kauf nehmen muss. Mit anderen Worten: Es gilt einen sinnvollen Kompromiss zwischen Modellgüte auf der einen und Modelltransparenz auf der anderen Seite zu finden.
Daher bietet es sich an, verschiedene Modelle mit unterschiedlichem Transparenzgrad auf demselben Datenbestand direkt gegeneinander zu vergleichen. Eine Möglichkeit, dies zu realisieren, stellt der SAS® Enterprise Miner™ dar. Er bietet mit dem Knoten Model Comparison direkt die Fähigkeit, verschiedene Modelle auf mehreren Gütekriterien zu vergleichen. Über die Knoten Model-Import und Open Source Integration können dabei auch eigene, ggf. SAS-externe (z.B. in R geschriebene) Modelle berücksichtigt werden:
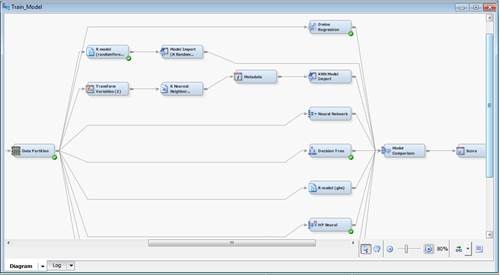
Sofern ein eher nicht-transparentes Modell (z.B. ein neuronales Netz) gegenüber einem transparentem Modell (z.B. logistische Regression) beim Vergleich der Anpassungsgüte (z.B. Fehlklassifikationsrate) dominiert, gibt dieses Vorgehen dann Aufschluss darüber, welches Ausmaß an Güte-Differenz noch tragbar wäre. Mit anderen Worten: Als Analyst kann ich nun entscheiden, welches Ausmaß an Prognosegüte-Verschlechterung ich als Trade-Off für bessere Transparenz in Kauf nehmen möchte.
