
Image recognition is a hot and hyped topic in machine learning, artificial intelligence and other technology circles. Computer vision technology is essential for realizing advancements like driverless cars, face recognition, medical outcomes predictions, and a host of other breakthrough innovations.
Amidst the hype, organizations large and small are trying to understand the specific industry use cases potential for the variety of underlying techniques and processes involved in image recognition. For experienced data miners, there are some required paradigm shifts to move from predictive modelling to image recognition. In this blog post, I’ll try to outline some of these new concepts, the challenges they pose and some means for addressing them.
Image processing is not image recognition
Image processing refers to a two-step process for preparing the image files for analysis and the subsequent fitting of algorithms to make selections or assign perceived qualities. Data preparation has always been important for building relevant and stable predictive models. Data tasks like standardization of continuous variables to a common scale, missing value imputation, and variable selection have been equally important to their algorithmic counterparts. This is not different for image recognition. The steps taken in image processing will directly impact whether downstream recognition will be feasible.
Let’s say an auto insurance company wants to pre-qualify customer car crashes by analyzing smartphone pictures of the crash. Image processing consists of more than simply converting the actual image files into binaries or flat characteristic tables. There may be certain attributes of the images that will have predictive value, and others that won’t.
Some questions we need to ask to determine what image processing steps are required include:
- Is color important?
- Does the image file contain multiple layers to provide 3D perspective?
- Can certain regions of the picture be omitted?
- Is it simply the edges of the image subject that are distinguishing the target event (in this case, a write-off or claim)?
- Do we want our training set to account for differences in camera angle?
- Does it make sense to enrich our training set with slight variations of some or all of the initial training images?
Each one of these questions can map to image processing actions to be applied. Any number of these actions can be combined to prepare a model training image set. Depending on the downstream modelling task, it makes sense to use image processing to amplify the signal (or conversely, reduce the noise).
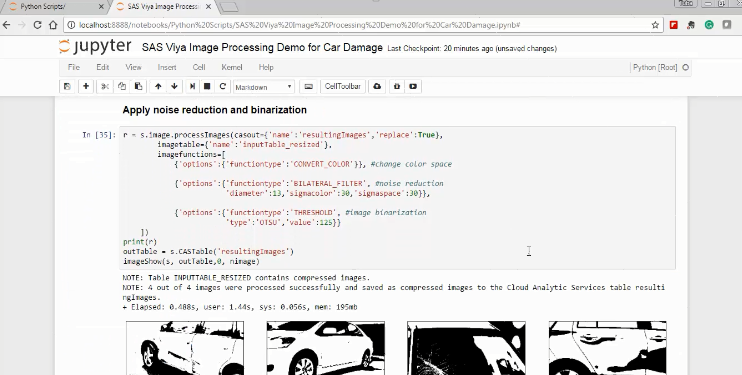
Figure 1: Applying SAS VIYA image processing actions in Jupyter Notebook
It is crucial to explore and understand the different options and ultimate importance of different image processing actions. The analyst should be empowered to try various approaches in an environment that allows for fail-fast experimentation and rapid deployment of demonstrated value approaches in direct combination with the subsequent image recognition algorithm.
Static images can be more powerful than dynamic images
Some image use cases are more complex than others as certain business contexts are more static than others. For example, in high-tech or general manufacturing contexts, taking pictures in a production line facility allows for images from a very consistent angle, with constant lighting and framing. These images can then be used to detect subtle changes in the production process which may be indicators for defects downstream.
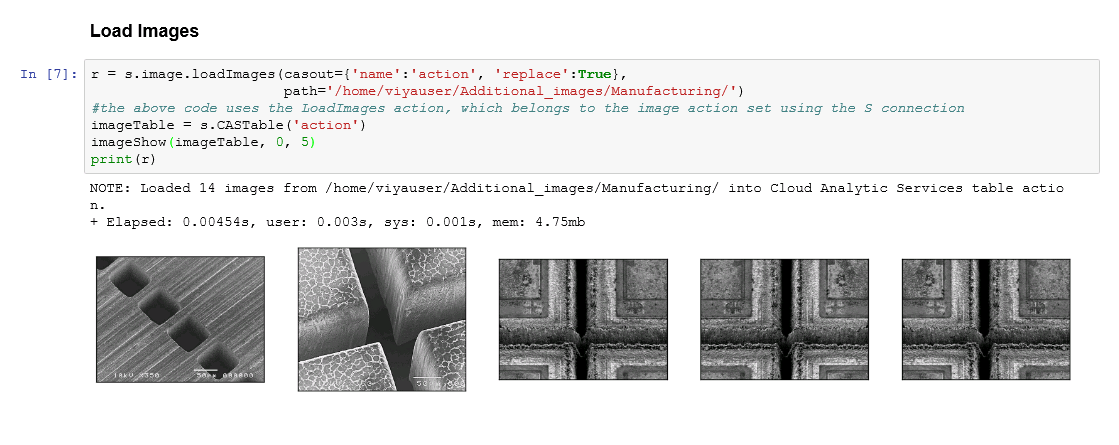
Figure 2: Sample images from semiconductor production line
In another example, public surveillance cameras taking pictures of crowds to spot criminals and criminal behavior control for angle and framing but lighting and subject will be variable.
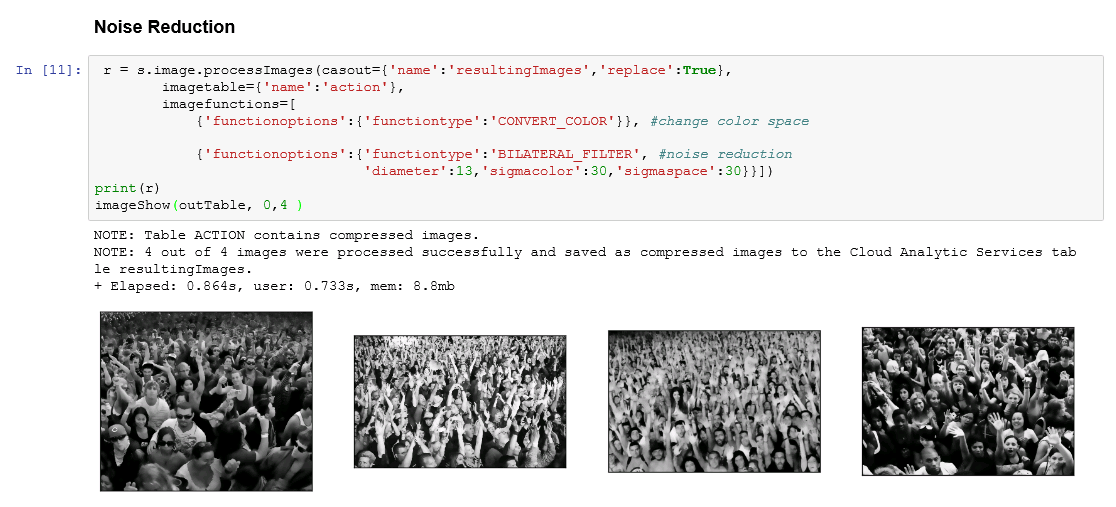
Fig3: Variations in lighting and subject can complicate target identification
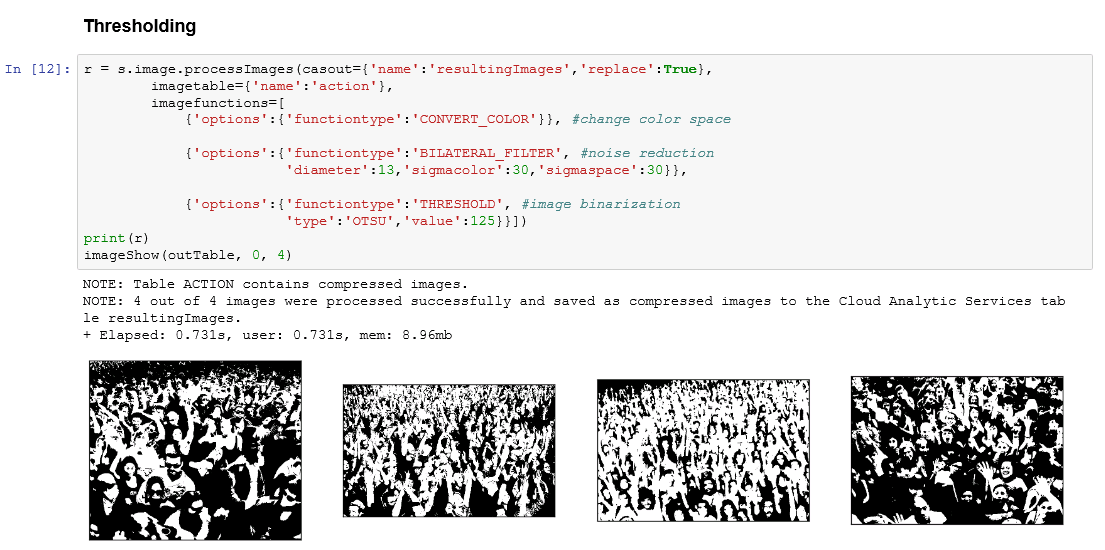
Figure 4: Image processing actions for noise reduction
Finally, if we return to our initial use case, an insurance company asking 100 people to take a picture of the same automobile accident will invariably get 100 different versions of the image truth. So when considering the image set for an analysis, in general, the more static the set is, the easier it will be to identify variants in the individual images and thus easier to recognize interesting patterns. In the case of the insurance company, it may make sense to offer customers an app which suggests consistent framing of the crash damage to allow for apples to apples comparisons.
Traditional and deep algorithms
“Choosing the simplest model that is up to the classification task” is a personal mantra that has served me well over the years in data analysis. A simpler model will tend to be more stable and is easier to explain to business stakeholders. On the other hand, image recognition, due to the complexity of information in an image, usually requires a more complex model. Deep learning algorithms like convolutional neural networks (CNN) are almost always required for any kind of real life image recognition classification task.
If you read up a bit on CNN, it begins to make sense that these algorithms have been most successful to date on image recognition challenges. In these highly complex neural landscapes, there is a certain amount of overlap between receptive fields of individual neurons, similar to the human visual cortex. Modern computing power enables these complex architectures to get ever closer to a human-like visual recognition capability (while potentially eliminating some of the detrimental bias and error).

Figure 5: Building a CNN with the upcoming Deep Learning Action Set from SAS VIYA
Again, it becomes crucial to explore and understand the different possible architectures of CNN for various image recognition challenges. The analyst should be empowered to compare and contrast various configurations in the same environment allowing for fail-fast experimentation and rapid deployment of demonstrated value approaches.
Innovation and results
I started this article by stating that image recognition does bring new challenges. That said, I do think we can take some lessons learned from the not-so-distant past when we started enriching data mining on structured data to include textual, and other forms of unstructured data. There is currently a lot of compelling literature on image recognition experimentation and processes. It is essential to read and keep up with these evolutions. That said, experience in operationalizing analytics is even more important if organizations want to realize any value from these very promising technologies and approaches.
Undoubtedly, image recognition is an exciting new frontier in data science and will enrich various business processes. Organizations who are successful in combining the latest and greatest technologies for image processing and recognition with an operationally robust analytics environment will benefit first.
Learn more about SAS Visual Data Mining and Machine Learning.

5 Comments
Would it be posisble to share the jupyter notebooks along with the blog post? 🙂
You can find the Jupyter notebook examples for image recognition and more here, on the SAS Software GitHub page: SAS Viya Machine Learning Examples
Check this out, https://github.com/egladysh/shadow
This is an awesome motivational article. I am practically satisfied with your excellent work. You put really extremely useful data. Keep it up like this. Keep blogging. Looking forward to reading your next post
Data science course in mangalore
Thanks for sharing this amazing article, keep posting.
full stack developer course in Hyderabad